MLS-C01 Amazon Web Services AWS Certified Machine Learning - Specialty Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Amazon Web Services MLS-C01 AWS Certified Machine Learning - Specialty certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
An e-commerce company needs a customized training model to classify images of its shirts and pants products The company needs a proof of concept in 2 to 3 days with good accuracy Which compute choice should the Machine Learning Specialist select to train and achieve good accuracy on the model quickly?
A data scientist uses Amazon SageMaker Data Wrangler to analyze and visualize data. The data scientist wants to refine a training dataset by selecting predictor variables that are strongly predictive of the target variable. The target variable correlates with other predictor variables.
The data scientist wants to understand the variance in the data along various directions in the feature space.
Which solution will meet these requirements?
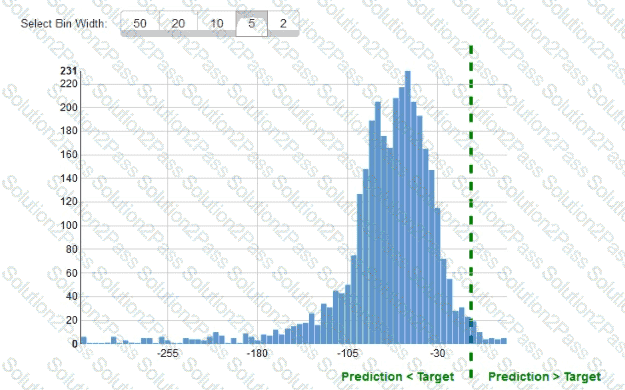
While reviewing the histogram for residuals on regression evaluation data a Machine Learning Specialist notices that the residuals do not form a zero-centered bell shape as shown What does this mean?
A retail company stores 100 GB of daily transactional data in Amazon S3 at periodic intervals. The company wants to identify the schema of the transactional data. The company also wants to perform transformations on the transactional data that is in Amazon S3.
The company wants to use a machine learning (ML) approach to detect fraud in the transformed data.
Which combination of solutions will meet these requirements with the LEAST operational overhead? {Select THREE.)
A data scientist receives a collection of insurance claim records. Each record includes a claim ID. the final outcome of the insurance claim, and the date of the final outcome.
The final outcome of each claim is a selection from among 200 outcome categories. Some claim records include only partial information. However, incomplete claim records include only 3 or 4 outcome ...gones from among the 200 available outcome categories. The collection includes hundreds of records for each outcome category. The records are from the previous 3 years.
The data scientist must create a solution to predict the number of claims that will be in each outcome category every month, several months in advance.
Which solution will meet these requirements?
A Machine Learning Specialist working for an online fashion company wants to build a data ingestion solution for the company's Amazon S3-based data lake.
The Specialist wants to create a set of ingestion mechanisms that will enable future capabilities comprised of:
• Real-time analytics
• Interactive analytics of historical data
• Clickstream analytics
• Product recommendations
Which services should the Specialist use?
A manufacturing company has structured and unstructured data stored in an Amazon S3 bucket A Machine Learning Specialist wants to use SQL to run queries on this data. Which solution requires the LEAST effort to be able to query this data?
A company wants to predict stock market price trends. The company stores stock market data each business day in Amazon S3 in Apache Parquet format. The company stores 20 GB of data each day for each stock code.
A data engineer must use Apache Spark to perform batch preprocessing data transformations quickly so the company can complete prediction jobs before the stock market opens the next day. The company plans to track more stock market codes and needs a way to scale the preprocessing data transformations.
Which AWS service or feature will meet these requirements with the LEAST development effort over time?
A machine learning specialist is developing a proof of concept for government users whose primary concern is security. The specialist is using Amazon SageMaker to train a convolutional neural network (CNN) model for a photo classifier application. The specialist wants to protect the data so that it cannot be accessed and transferred to a remote host by malicious code accidentally installed on the training container.
Which action will provide the MOST secure protection?
A large consumer goods manufacturer has the following products on sale
• 34 different toothpaste variants
• 48 different toothbrush variants
• 43 different mouthwash variants
The entire sales history of all these products is available in Amazon S3 Currently, the company is using custom-built autoregressive integrated moving average (ARIMA) models to forecast demand for these products The company wants to predict the demand for a new product that will soon be launched
Which solution should a Machine Learning Specialist apply?
A bank's Machine Learning team is developing an approach for credit card fraud detection The company has a large dataset of historical data labeled as fraudulent The goal is to build a model to take the information from new transactions and predict whether each transaction is fraudulent or not
Which built-in Amazon SageMaker machine learning algorithm should be used for modeling this problem?
A company is building a new supervised classification model in an AWS environment. The company's data science team notices that the dataset has a large quantity of variables Ail the variables are numeric. The model accuracy for training and validation is low. The model's processing time is affected by high latency The data science team needs to increase the accuracy of the model and decrease the processing.
How it should the data science team do to meet these requirements?
A data scientist needs to identify fraudulent user accounts for a company's ecommerce platform. The company wants the ability to determine if a newly created account is associated with a previously known fraudulent user. The data scientist is using AWS Glue to cleanse the company's application logs during ingestion.
Which strategy will allow the data scientist to identify fraudulent accounts?
A machine learning specialist stores IoT soil sensor data in Amazon DynamoDB table and stores weather event data as JSON files in Amazon S3. The dataset in DynamoDB is 10 GB in size and the dataset in Amazon S3 is 5 GB in size. The specialist wants to train a model on this data to help predict soil moisture levels as a function of weather events using Amazon SageMaker.
Which solution will accomplish the necessary transformation to train the Amazon SageMaker model with the LEAST amount of administrative overhead?
A real estate company wants to create a machine learning model for predicting housing prices based on a
historical dataset. The dataset contains 32 features.
Which model will meet the business requirement?
A Data Scientist needs to analyze employment data. The dataset contains approximately 10 million
observations on people across 10 different features. During the preliminary analysis, the Data Scientist notices
that income and age distributions are not normal. While income levels shows a right skew as expected, with fewer individuals having a higher income, the age distribution also show a right skew, with fewer older
individuals participating in the workforce.
Which feature transformations can the Data Scientist apply to fix the incorrectly skewed data? (Choose two.)
A company is building a demand forecasting model based on machine learning (ML). In the development stage, an ML specialist uses an Amazon SageMaker notebook to perform feature engineering during work hours that consumes low amounts of CPU and memory resources. A data engineer uses the same notebook to perform data preprocessing once a day on average that requires very high memory and completes in only 2 hours. The data preprocessing is not configured to use GPU. All the processes are running well on an ml.m5.4xlarge notebook instance.
The company receives an AWS Budgets alert that the billing for this month exceeds the allocated budget.
Which solution will result in the MOST cost savings?
A company wants to predict the sale prices of houses based on available historical sales data. The target
variable in the company’s dataset is the sale price. The features include parameters such as the lot size, living
area measurements, non-living area measurements, number of bedrooms, number of bathrooms, year built,
and postal code. The company wants to use multi-variable linear regression to predict house sale prices.
Which step should a machine learning specialist take to remove features that are irrelevant for the analysis
and reduce the model’s complexity?
A Machine Learning Specialist is working with a large company to leverage machine learning within its products. The company wants to group its customers into categories based on which customers will and will not churn within the next 6 months. The company has labeled the data available to the Specialist.
Which machine learning model type should the Specialist use to accomplish this task?
A Data Scientist needs to create a serverless ingestion and analytics solution for high-velocity, real-time streaming data.
The ingestion process must buffer and convert incoming records from JSON to a query-optimized, columnar format without data loss. The output datastore must be highly available, and Analysts must be able to run SQL queries against the data and connect to existing business intelligence dashboards.
Which solution should the Data Scientist build to satisfy the requirements?
