C1000-059 IBM AI Enterprise Workflow V1 Data Science Specialist Free Practice Exam Questions (2026 Updated)
Prepare effectively for your IBM C1000-059 IBM AI Enterprise Workflow V1 Data Science Specialist certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
What are three operators used by genetic programming? (Choose three.)
What are two key characteristics of cloud architecture that could benefit AI applications? (Choose two.)
Which fine-tuning technique does not optimize the hyperparameters of a machine learning model?
What are three elements that are typically part of a machine learning pipeline in scikit-learn or pyspark? (Choose three.)
Which is a preferred approach for simplifying the data transformation steps in machine learning model management and maintenance?
What is the first step in creating a custom model in Watson Visual Recognition service?
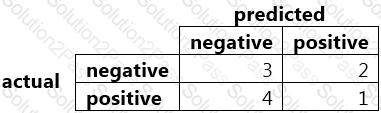
The formula for recall is given by (True Positives) / (True Positives + False Negatives). What is the recall for this example?
What are two methods used to detect outliers in structured data? (Choose two.)
What is used to scale large positive values during data cleaning?
Which IBM Watson Machine Learning deployment method offers the ultimate flexibility in deploying a machine learning model?
A classification task has examples that are labeled as belonging to one of two classes:
•90% of the examples belong to class-1
•10% belong to class-2
Which two techniques are appropriate to deal with the class imbalance? (Choose two.)
Considering one ML application is deployed using Kubernetes, its output depends on the data which is constantly stored in the model, if needing to scale the system based on available CPUs, what feature should be enabled?
Given the following sentence:
The dog jumps over a fence.
What would a vectorized version after common English stopword removal look like?
What is the meaning of "deep" in deep learning?
Which is the most important thing to ensure while collecting data?
Which situation would disqualify a machine learning system from being used for a particular use case?
A neural network is trained for a classification task. During training, you monitor the loss function for the train dataset and the validation dataset, along with the accuracy for the validation dataset. The goal is to get an accuracy of 95%.
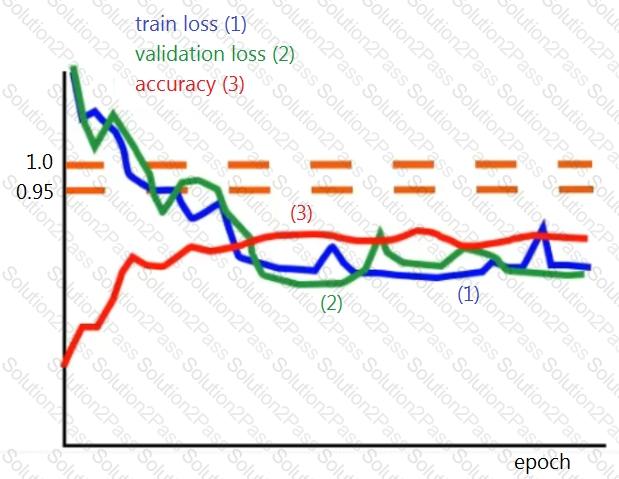
From the graph, what modification would be appropriate to improve the performance of the model?
Which algorithm is best suited if a client needs full explainability of the machine learning model?
