DP-100 Microsoft Designing and Implementing a Data Science Solution on Azure Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Microsoft DP-100 Designing and Implementing a Data Science Solution on Azure certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
You use the following Python code in a notebook to deploy a model as a web service:

The deployment fails.
You need to use the Python SDK in the notebook to determine the events that occurred during service deployment an initialization.
Which code segment should you use?
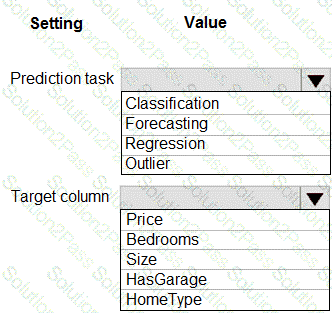
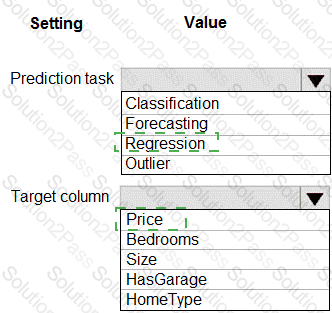
You have a dataset that includes home sales data for a city. The dataset includes the following columns.

Each row in the dataset corresponds to an individual home sales transaction.
You need to use automated machine learning to generate the best model for predicting the sales price based on the features of the house.
Which values should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You create a multi-class image classification deep learning model.
The model must be retrained monthly with the new image data fetched from a public web portal. You create an Azure Machine Learning pipeline to fetch new data, standardize the size of images and retrain the model.
You need to use the Azure Machine Learning Python SEX v2 to configure the schedule for the pipeline. The schedule should be defined by using the frequency and interval properties with frequency set to month' and interval set to "1:
Which three classes should you instantiate in sequence"' To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


: 211
You create an Azure Machine Learning workspace.
You must create a custom role named DataScientist that meets the following requirements:
Role members must not be able to delete the workspace.
Role members must not be able to create, update, or delete compute resource in the workspace.
Role members must not be able to add new users to the workspace.
You need to create a JSON file for the DataScientist role in the Azure Machine Learning workspace.
The custom role must enforce the restrictions specified by the IT Operations team.
Which JSON code segment should you use?
A)

B)

C)
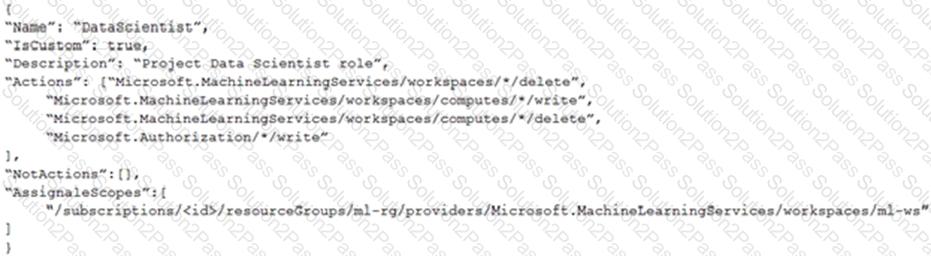
D)

You are building recurrent neural network to perform a binary classification.
The training loss, validation loss, training accuracy, and validation accuracy of each training epoch has been provided. You need to identify whether the classification model is over fitted.
Which of the following is correct?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create a model to forecast weather conditions based on historical data.
You need to create a pipeline that runs a processing script to load data from a datastore and pass the processed data to a machine learning model training script.
Solution: Run the following code:
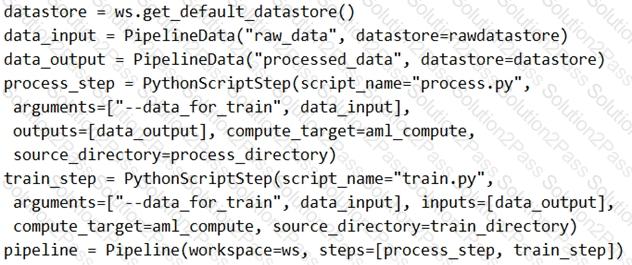
Does the solution meet the goal?
You manage an Azure Machine Learning workspace. You create an experiment named experiment1 by using the Azure Machine Learning Python SDK v2 and MLflow.
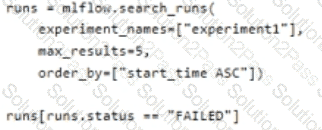
For each of the following statements, select Yes if the statement is true. Otherwise, select No.


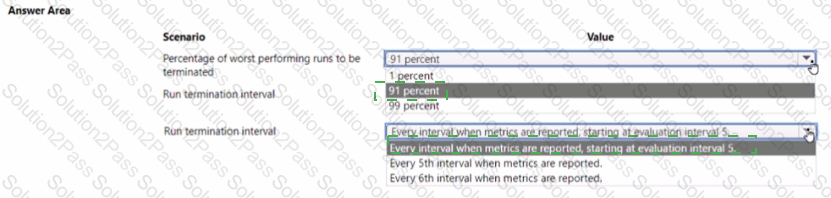
You use Azure Machine Learning to implement hyperparameter tuning with a Bandit early termination policy.
The policy uses a slack_factor set to 01. an evaluation interval set to 1, and an evaluation delay set to b.
You need to evaluate the outcome of the early termination policy
What should you evaluate? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.

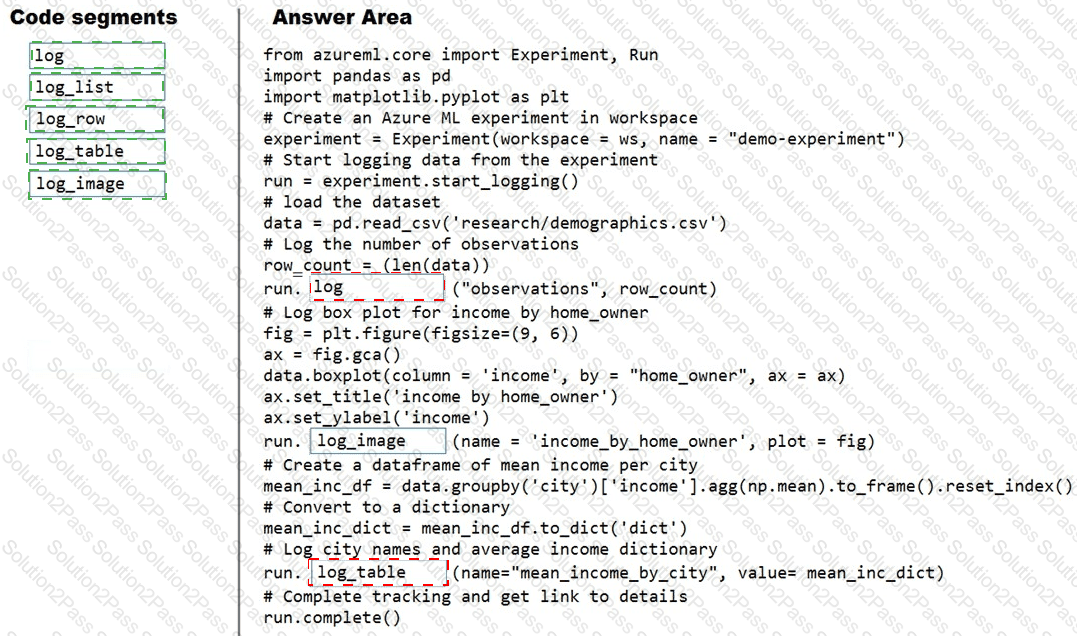
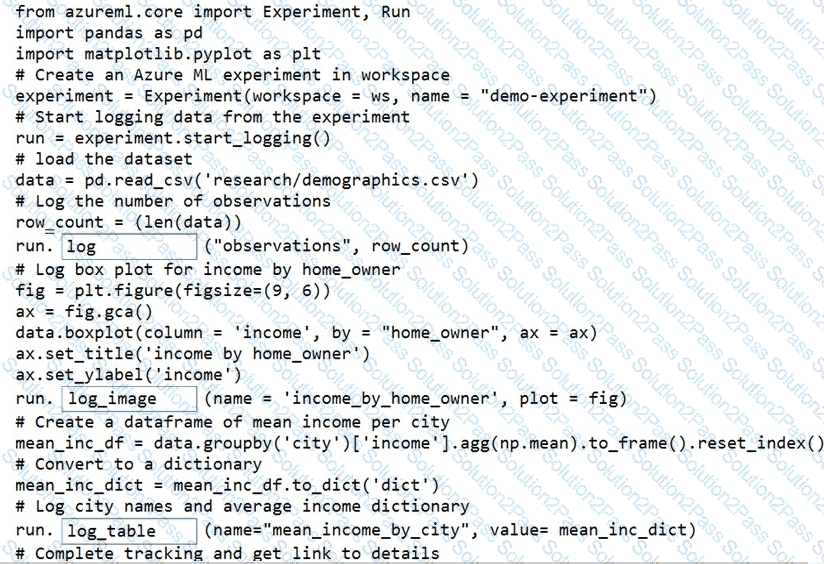
You plan to explore demographic data for home ownership in various cities. The data is in a CSV file with the following format:
age,city,income,home_owner
21,Chicago,50000,0
35,Seattle,120000,1
23,Seattle,65000,0
45,Seattle,130000,1
18,Chicago,48000,0
You need to run an experiment in your Azure Machine Learning workspace to explore the data and log the results. The experiment must log the following information:
the number of observations in the dataset
a box plot of income by home_owner
a dictionary containing the city names and the average income for each city
You need to use the appropriate logging methods of the experiment’s run object to log the required information.
How should you complete the code? To answer, drag the appropriate code segments to the correct locations. Each code segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You use the Azure Machine Learning Python SDK to define a pipeline to train a model.
The data used to train the model is read from a folder in a datastore.
You need to ensure the pipeline runs automatically whenever the data in the folder changes.
What should you do?
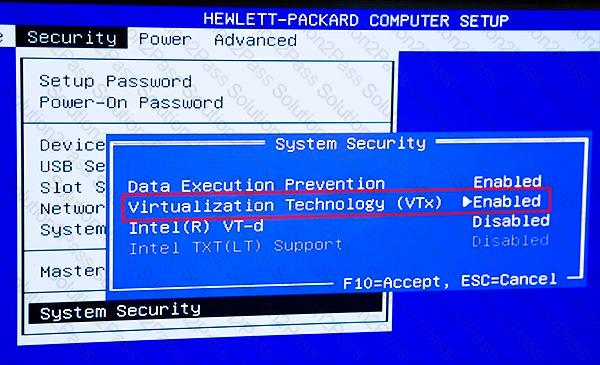
You are developing a hands-on workshop to introduce Docker for Windows to attendees.
You need to ensure that workshop attendees can install Docker on their devices.
Which two prerequisite components should attendees install on the devices? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You manage an Azure Machine learning workspace. You develop a machine teaming model.
You are deploying the model to use a low-pointy VM mm a pacing discount.
You need to deploy the model.
Which compute large! should you use?
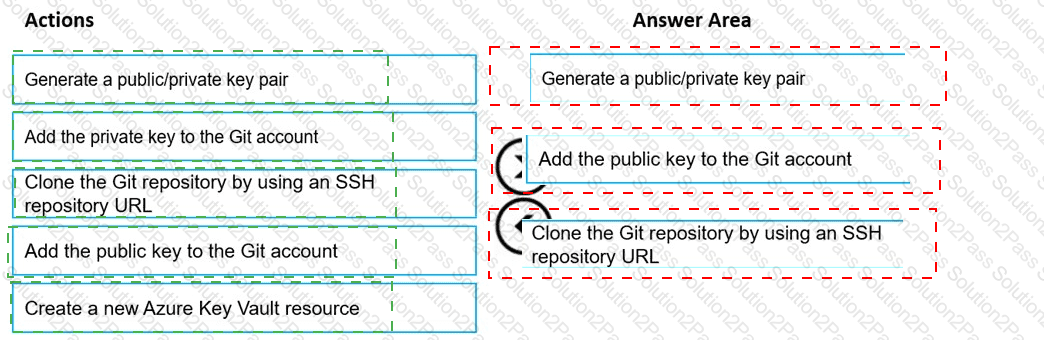
You are using a Git repository to track work in an Azure Machine Learning workspace.
You need to authenticate a Git account by using SSH.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You are authoring a notebook in Azure Machine Learning studio.
You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only.
You need to install the packages.
Which magic function should you use?
You need to implement source control for scripts in an Azure Machine Learning workspace. You use a terminal window in the Azure Machine Learning Notebook tab
You must authenticate your Git account with SSH.
You need to generate a new SSH key.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them m the correct order.


You manage an Azure Al Foundry project.
You plan to develop a RAG solution from a set of PDF files. To achieve this, you plan to create a vector index from the data. You need to select the location of the data you plan to index.
Which two data sources can you use? Each correct answer presents a complete solution. Choose two. NOTE: Each correct selection is worth one point.
You are the owner of an Azure Machine Learning workspace.
You must prevent the creation or deletion of compute resources by using a custom role. You must allow all other operations inside the workspace.
You need to configure the custom role.
How should you complete the configuration? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.




You are using Azure Machine Learning to monitor a trained and deployed model. You implement Event Grid to respond to Azure Machine Learning events.
Model performance has degraded due to model input data changes.
You need to trigger a remediation ML pipeline based on an Azure Machine Learning event.
Which event should you use?
You manage an Azure Machine Learning workspace. The development environment is configured with a Serverless Spark compute in Azure Machine Learning Notebooks.
You perform interactive data wrangling to clean up the Titanic dataset and store it as a new dataset (Line numbers are used for reference only.)
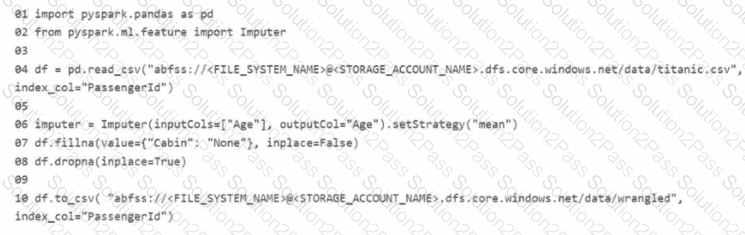
For each of the following statements, select Yes if the statement is true Otherwise, select No
NOTE: Bach correct selection is worth one point.


You have an Azure Machine Learning workspace.
You plan to tune a model hyperparameter when you train the model.
You need to define a search space that returns a normally distributed value.
Which parameter should you use?
