MLA-C01 Amazon Web Services AWS Certified Machine Learning Engineer - Associate Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Amazon Web Services MLA-C01 AWS Certified Machine Learning Engineer - Associate certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
A company is using an Amazon Redshift database as its single data source. Some of the data is sensitive.
A data scientist needs to use some of the sensitive data from the database. An ML engineer must give the data scientist access to the data without transforming the source data and without storing anonymized data in the database.
Which solution will meet these requirements with the LEAST implementation effort?
A company has implemented a data ingestion pipeline for sales transactions from its ecommerce website. The company uses Amazon Data Firehose to ingest data into Amazon OpenSearch Service. The buffer interval of the Firehose stream is set for 60 seconds. An OpenSearch linear model generates real-time sales forecasts based on the data and presents the data in an OpenSearch dashboard.
The company needs to optimize the data ingestion pipeline to support sub-second latency for the real-time dashboard.
Which change to the architecture will meet these requirements?
A company has an ML model that needs to run one time each night to predict stock values. The model input is 3 MB of data that is collected during the current day. The model produces the predictions for the next day. The prediction process takes less than 1 minute to finish running.
How should the company deploy the model on Amazon SageMaker to meet these requirements?
A company has used Amazon SageMaker to deploy a predictive ML model in production. The company is using SageMaker Model Monitor on the model. After a model update, an ML engineer notices data quality issues in the Model Monitor checks.
What should the ML engineer do to mitigate the data quality issues that Model Monitor has identified?
An ML engineer is training an XGBoost regression model in Amazon SageMaker AI. The ML engineer conducts several rounds of hyperparameter tuning with random grid search. After these rounds of tuning, the error rate on the test hold-out dataset is much larger than the error rate on the training dataset.
The ML engineer needs to make changes before running the hyperparameter grid search again.
Which changes will improve the model ' s performance? (Select TWO.)
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer decides to use Amazon SageMaker AI automated model tuning (AMT) for hyperparameter optimization (HPO). The ML engineer requires a tuning strategy that uses regression to slowly and sequentially select the next set of hyperparameters based on previous runs. The strategy must work across small hyperparameter ranges.
Which solution will meet these requirements?
An ML engineer is using an Amazon SageMaker AI shadow test to evaluate a new model that is hosted on a SageMaker AI endpoint. The shadow test requires significant GPU resources for high performance. The production variant currently runs on a less powerful instance type.
The ML engineer needs to configure the shadow test to use a higher performance instance type for a shadow variant. The solution must not affect the instance type of the production variant.
Which solution will meet these requirements?
A company runs an Amazon SageMaker domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
A company has a custom extract, transform, and load (ETL) process that runs on premises. The ETL process is written in the R language and runs for an average of 6 hours. The company wants to migrate the process to run on AWS.
Which solution will meet these requirements?
A company is building a near real-time data analytics application to detect anomalies and failures for industrial equipment. The company has thousands of IoT sensors that send data every 60 seconds. When new versions of the application are released, the company wants to ensure that application code bugs do not prevent the application from running.
Which solution will meet these requirements?
An ML engineer is building a model to predict house and apartment prices. The model uses three features: Square Meters, Price, and Age of Building. The dataset has 10,000 data rows. The data includes data points for one large mansion and one extremely small apartment.
The ML engineer must perform preprocessing on the dataset to ensure that the model produces accurate predictions for the typical house or apartment.
Which solution will meet these requirements?
An ML engineer is preparing a dataset that contains medical records to train an ML model to predict the likelihood of patients developing diseases.
The dataset contains columns for patient ID, age, medical conditions, test results, and a " Disease " target column.
How should the ML engineer configure the data to train the model?
An ML engineer wants to run a training job on Amazon SageMaker AI. The training job will train a neural network by using multiple GPUs. The training dataset is stored in Parquet format.
The ML engineer discovered that the Parquet dataset contains files too large to fit into the memory of the SageMaker AI training instances.
Which solution will fix the memory problem?
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of data quality for the models and must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
A company is using an ML model to classify motion in videos. The data is stored in MP4 format in Amazon S3. When the company created the model, the company needed 4 months to label all the video frames.
The company needs to retrain the model with an existing training workflow in Amazon SageMaker AI. An ML engineer must implement a solution that decreases the labeling time.
Which solution will meet these requirements?
An ML engineer is building an ML model in Amazon SageMaker AI. The ML engineer needs to load historical data directly from Amazon S3, Amazon Athena, and Snowflake into SageMaker AI.
Which solution will meet this requirement?
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model ' s performance?
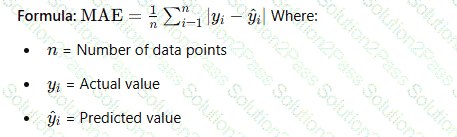
A company has a binary classification model in production. An ML engineer needs to develop a new version of the model.
The new model version must maximize correct predictions of positive labels and negative labels. The ML engineer must use a metric to recalibrate the model to meet these requirements.
Which metric should the ML engineer use for the model recalibration?
A company is developing an ML model for a customer. The training data is stored in an Amazon S3 bucket in the customer ' s AWS account (Account A). The company runs Amazon SageMaker AI training jobs in a separate AWS account (Account B).
The company defines an S3 bucket policy and an IAM policy to allow reads to the S3 bucket.
Which additional steps will meet the cross-account access requirement?
