MLA-C01 Amazon Web Services AWS Certified Machine Learning Engineer - Associate Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Amazon Web Services MLA-C01 AWS Certified Machine Learning Engineer - Associate certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
A company wants to migrate ML models from an on-premises environment to Amazon SageMaker AI. The models are based on the PyTorch algorithm. The company needs to reuse its existing custom scripts as much as possible.
Which SageMaker AI feature should the company use?
A company uses an NFS-based data store to store data for ML training. Linux-based systems access the data store.
The company needs a hybrid system to make the shared data store accessible to on-premises servers and Amazon SageMaker AI notebooks that will consume the data. File locking is required for the data producers.
Which AWS storage solution will meet these requirements?
A company is developing an internal cost-estimation tool that uses an ML model in Amazon SageMaker AI. Users upload high-resolution images to the tool.
The model must process each image and predict the cost of the object in the image. The model also must notify the user when processing is complete.
Which solution will meet these requirements?
A company is using an AWS Lambda function to monitor the metrics from an ML model. An ML engineer needs to implement a solution to send an email message when the metrics breach a threshold.
Which solution will meet this requirement?
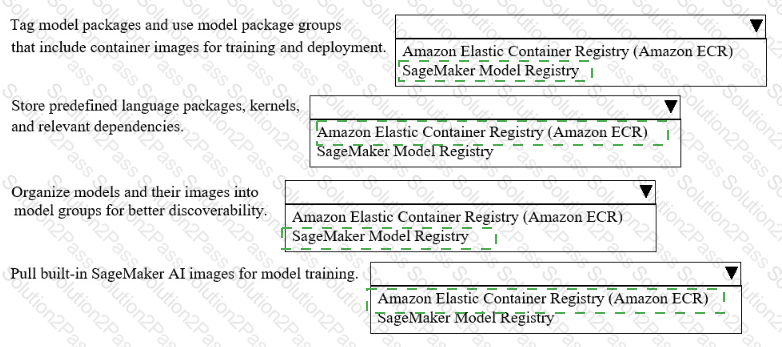
A company uses Amazon SageMakerAI to support ML workflows such as model training and deployment.
Select the correct registry from the following list to meet the requirements for each use case with the LEAST operational overhead. Each registry should be selected one or more times. (Select FOUR.)
• Amazon Elastic Container Registry (Amazon ECR)
• SageMaker Model Registry

A company ' s ML engineer is creating a classification model. The ML engineer explores the dataset and notices a column named day_of_week. The column contains the following values: Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday.
Which technique should the ML engineer use to convert this column’s data to binary values?
Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model ' s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
The training dataset includes categorical data and numerical data. The ML engineer must prepare the training dataset to maximize the accuracy of the model.
Which action will meet this requirement with the LEAST operational overhead?
A company stores training data as a .csv file in an Amazon S3 bucket. The company must encrypt the data and must control which applications have access to the encryption key.
Which solution will meet these requirements?
A company wants to predict the success of advertising campaigns by considering the color scheme of each advertisement. An ML engineer is preparing data for a neural network model. The dataset includes color information as categorical data.
Which technique for feature engineering should the ML engineer use for the model?
An ML engineer develops a neural network model to predict whether customers will continue to subscribe to a service. The model performs well on training data. However, the accuracy of the model decreases significantly on evaluation data.
The ML engineer must resolve the model performance issue.
Which solution will meet this requirement?
An ML engineer is tuning an image classification model that performs poorly on one of two classes. The poorly performing class represents an extremely small fraction of the training dataset.
Which solution will improve the model’s performance?
An ML engineer is developing a classification model. The ML engineer needs to use custom libraries in processing jobs, training jobs, and pipelines in Amazon SageMaker AI.
Which solution will provide this functionality with the LEAST implementation effort?
A company is creating an application that will recommend products for customers to purchase. The application will make API calls to Amazon Q Business. The company must ensure that responses from Amazon Q Business do not include the name of the company ' s main competitor.
Which solution will meet this requirement?
A music streaming company constantly streams song ratings from an application to an Amazon S3 bucket. The company wants to use the ratings as an input for training and inference of an Amazon SageMaker AI model.
The company has an AWS Glue Data Catalog that is configured with the S3 bucket as the source. An ML engineer needs to implement a solution to create a repository for this data. The solution must ensure that the data stays synchronized during batch training and real-time inference.
Which solution will meet these requirements?
A company is developing an ML model to predict customer satisfaction. The company needs to use survey feedback and the past satisfaction level of customers to predict the future satisfaction level of customers.
The dataset includes a column named Feedback that contains long text responses. The dataset also includes a column named Satisfaction Level that contains three distinct values for past customer satisfaction: High, Medium, and Low. The company must apply encoding methods to transform the data in each column.
Which solution will meet these requirements?
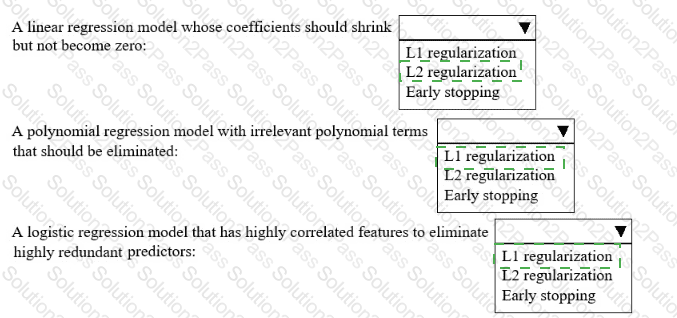
A hospital wants to predict patient outcomes for the coming year An ML engineer must improve several existing ML models that currently perform poorly.
Select the correct regularization method from the following list to improve each model Select each regularization method one time, more than one time, or not at all. (Select THREE.)
• L1 regularization
• L2 regularization
• Early stopping

A company uses Amazon SageMaker for its ML workloads. The company ' s ML engineer receives a 50 MB Apache Parquet data file to build a fraud detection model. The file includes several correlated columns that are not required.
What should the ML engineer do to drop the unnecessary columns in the file with the LEAST effort?
A company has significantly increased the amount of data stored as .csv files in an Amazon S3 bucket. Data transformation scripts and queries are now taking much longer than before.
An ML engineer must implement a solution to optimize the data for query performance with the LEAST operational overhead.
Which solution will meet this requirement?
A digital media entertainment company needs real-time video content moderation to ensure compliance during live streaming events.
Which solution will meet these requirements with the LEAST operational overhead?
