DY0-001 CompTIA DataX Exam Free Practice Exam Questions (2026 Updated)
Prepare effectively for your CompTIA DY0-001 CompTIA DataX Exam certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
A data analyst wants to use compression on an analyzed data set and send it to a new destination for further processing. Which of the following issues will most likely occur?
A data scientist is building a proof of concept for a commercialized machine-learning model. Which of the following is the best starting point?
A data scientist is designing a real-time machine-learning model that classifies a user based on initial behavior. The run times of these models are provided in the following table:
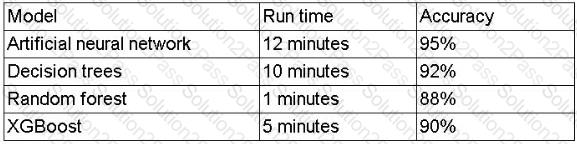
Which of the following models should the data scientist recommend for deployment?
Which of the following best describes the minimization of the residual term in a LASSO linear regression?
Which of the following measures would a data scientist most likely use to calculate the similarity of two text strings?
Which of the following best describes the minimization of the residual term in a ridge linear regression?
A data scientist is presenting the recommendations from a monthslong modeling and experiment process to the company’s Chief Executive Officer. Which of the following is the best set of artifacts to include in the presentation?
Given a logistics problem with multiple constraints (fuel, capacity, speed), which of the following is the most likely optimization technique a data scientist would apply?
Which of the following distributions would be best to use for hypothesis testing on a data set with 20 observations?
Which of the following image data augmentation techniques allows a data scientist to increase the size of a data set?
A data scientist is merging two tables. Table 1 contains employee IDs and roles. Table 2 contains employee IDs and team assignments. Which of the following is the best technique to combine these data sets?
A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
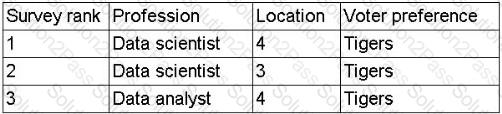
(Screenshot shows survey rankings for just two professions and a few locations, all voting for "Tigers")
Which of the following is the most likely concern about the model's ability to predict the outcome of the vote?
Given matrix
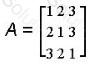
Which of the following is AT?



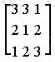
A data scientist trained a model for departments to share. The departments must access the model using HTTP requests. Which of the following approaches is appropriate?
Which of the following methods should a data scientist use just before switching to a potential replacement model?
Which of the following is a key difference between KNN and k-means machine-learning techniques?
A data scientist needs to analyze a company's chemical businesses and is using the master database of the conglomerate company. Nothing in the data differentiates the data observations for the different businesses. Which of the following is the most efficient way to identify the chemical businesses' observations?
Which of the following types of machine learning is a GPU most commonly used for?
In a modeling project, people evaluate phrases and provide reactions as the target variable for the model. Which of the following best describes what this model is doing?
A data scientist is analyzing a data set with categorical features and would like to make those features more useful when building a model. Which of the following data transformation techniques should the data scientist use? (Choose two.)
