Professional-Cloud-Developer Google Certified Professional - Cloud Developer Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Google Professional-Cloud-Developer Google Certified Professional - Cloud Developer certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
Total 265 questions
You need to deploy an internet-facing microservices application to Google Kubernetes Engine (GKE). You want to validate new features using the A/B testing method. You have the following requirements for deploying new container image releases
• There is no downtime when new container images are deployed.
• New production releases are tested and verified using a subset of production users.
What should you do?
Your API backend is running on multiple cloud providers. You want to generate reports for the network latency of your API.
Which two steps should you take? (Choose two.)
You are a lead developer working on a new retail system that runs on Cloud Run and Firestore. A web UI requirement is for the user to be able to browse through alt products. A few months after go-live, you notice that Cloud Run instances are terminated with HTTP 500: Container instances are exceeding memory limits errors during busy times
This error coincides with spikes in the number of Firestore queries
You need to prevent Cloud Run from crashing and decrease the number of Firestore queries. You want to use a solution that optimizes system performance What should you do?
Your analytics system executes queries against a BigQuery dataset. The SQL query is executed in batch and passes the contents of a SQL file to the BigQuery CLI. Then it redirects the BigQuery CLI output to another process. However, you are getting a permission error from the BigQuery CLI when the queries are executed. You want to resolve the issue. What should you do?
You are a developer at a large organization. You have an application written in Go running in a production Google Kubernetes Engine (GKE) cluster. You need to add a new feature that requires access to BigQuery. You want to grant BigQuery access to your GKE cluster following Google-recommended best practices. What should you do?
You recently deployed a Go application on Google Kubernetes Engine (GKE). The operations team has noticed that the application's CPU usage is high even when there is low production traffic. The operations team has asked you to optimize your application's CPU resource consumption. You want to determine which Go functions consume the largest amount of CPU. What should you do?
You manage an ecommerce application that processes purchases from customers who can subsequently cancel or change those purchases. You discover that order volumes are highly variable and the backend order-processing system can only process one request at a time. You want to ensure seamless performance for customers regardless of usage volume. It is crucial that customers’ order update requests are performed in the sequence in which they were generated. What should you do?
You are using the Cloud Client Library to upload an image in your application to Cloud Storage. Users of the application report that occasionally the upload does not complete and the client library reports an HTTP 504 Gateway Timeout error. You want to make the application more resilient to errors. What changes to the application should you make?
You are creating a Google Kubernetes Engine (GKE) cluster and run this command:
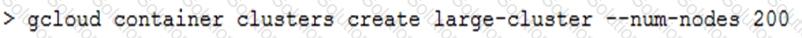
The command fails with the error:

You want to resolve the issue. What should you do?
You have containerized a legacy application that stores its configuration on an NFS share. You need to deploy this application to Google Kubernetes Engine (GKE) and do not want the application serving traffic until after the configuration has been retrieved. What should you do?
You are designing a deployment technique for your new applications on Google Cloud. As part of your deployment planning, you want to use live traffic to gather performance metrics for both new and existing applications. You need to test against the full production load prior to launch. What should you do?
You are reviewing and updating your Cloud Build steps to adhere to Google-recommended practices. Currently, your build steps include:
1. Pull the source code from a source repository.
2. Build a container image
3. Upload the built image to Artifact Registry.
You need to add a step to perform a vulnerability scan of the built container image, and you want the results of the scan to be available to your deployment pipeline running in Google Cloud. You want to minimize changes that could disrupt other teams' processes What should you do?
You recently migrated an on-premises monolithic application to a microservices application on Google Kubernetes Engine (GKE). The application has dependencies on backend services on-premises, including a CRM system and a MySQL database that contains personally identifiable information (PII). The backend services must remain on-premises to meet regulatory requirements.
You established a Cloud VPN connection between your on-premises data center and Google Cloud. You notice that some requests from your microservices application on GKE to the backend services are failing due to latency issues caused by fluctuating bandwidth, which is causing the application to crash. How should you address the latency issues?
You are designing a chat room application that will host multiple rooms and retain the message history for each room. You have selected Firestore as your database. How should you represent the data in Firestore?
Create a collection for the rooms. For each room, create a document that lists the contents of the messages
Create a collection for the rooms. For each room, create a collection that contains a document for each message

Create a collection for the rooms. For each room, create a document that contains a collection for documents, each of which contains a message.

Create a collection for the rooms, and create a document for each room. Create a separate collection for messages, with one document per message. Each room’s document contains a list of references to the messages.
Your company has a BigQuery dataset named "Master" that keeps information about employee travel and
expenses. This information is organized by employee department. That means employees should only be able
to view information for their department. You want to apply a security framework to enforce this requirement
with the minimum number of steps.
What should you do?
You are evaluating developer tools to help drive Google Kubernetes Engine adoption and integration with your development environment, which includes VS Code and IntelliJ. What should you do?
You are using Cloud Build to create a new Docker image on each source code commit to a Cloud Source Repositoties repository. Your application is built on every commit to the master branch. You want to release specific commits made to the master branch in an automated method. What should you do?
You want to notify on-call engineers about a service degradation in production while minimizing development
time.
What should you do?
You are developing a JPEG image-resizing API hosted on Google Kubernetes Engine (GKE). Callers of the service will exist within the same GKE cluster. You want clients to be able to get the IP address of the service.
What should you do?
You are developing a new public-facing application that needs to retrieve specific properties in the metadata of users’ objects in their respective Cloud Storage buckets. Due to privacy and data residency requirements, you must retrieve only the metadata and not the object data. You want to maximize the performance of the retrieval process. How should you retrieve the metadata?
Total 265 questions
