Professional-Cloud-Developer Google Certified Professional - Cloud Developer Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Google Professional-Cloud-Developer Google Certified Professional - Cloud Developer certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
Total 265 questions
You are using Cloud Build to build a Docker image. You need to modify the build to execute unit and run
integration tests. When there is a failure, you want the build history to clearly display the stage at which the
build failed.
What should you do?
Your team is developing unit tests for Cloud Function code. The code is stored in a Cloud Source Repositories repository. You are responsible for implementing the tests. Only a specific service account has the necessary permissions to deploy the code to Cloud Functions. You want to ensure that the code cannot be deployed without first passing the tests. How should you configure the unit testing process?
Your application takes an input from a user and publishes it to the user's contacts. This input is stored in a
table in Cloud Spanner. Your application is more sensitive to latency and less sensitive to consistency.
How should you perform reads from Cloud Spanner for this application?
You are deploying a microservices application to Google Kubernetes Engine (GKE) that will broadcast livestreams. You expect unpredictable traffic patterns and large variations in the number of concurrent users. Your application must meet the following requirements:
• Scales automatically during popular events and maintains high availability
• Is resilient in the event of hardware failures
How should you configure the deployment parameters? (Choose two.)
You need to configure a Deployment on Google Kubernetes Engine (GKE). You want to include a check that verifies that the containers can connect to the database. If the Pod is failing to connect, you want a script on the container to run to complete a graceful shutdown. How should you configure the Deployment?
Your application performs well when tested locally, but it runs significantly slower when you deploy it to App Engine standard environment. You want to diagnose the problem. What should you do?
Your team develops services that run on Google Cloud. You want to process messages sent to a Pub/Sub topic, and then store them. Each message must be processed exactly once to avoid duplication of data and any data conflicts. You need to use the cheapest and most simple solution. What should you do?
You manage an application that runs in a Compute Engine instance. You also have multiple backend services executing in stand-alone Docker containers running in Compute Engine instances. The Compute Engine instances supporting the backend services are scaled by managed instance groups in multiple regions. You want your calling application to be loosely coupled. You need to be able to invoke distinct service implementations that are chosen based on the value of an HTTP header found in the request. Which Google Cloud feature should you use to invoke the backend services?
You are writing a Compute Engine hosted application in project A that needs to securely authenticate to a Cloud Pub/Sub topic in project B.
What should you do?
You are developing an application that will store and access sensitive unstructured data objects in a Cloud Storage bucket. To comply with regulatory requirements, you need to ensure that all data objects are available for at least 7 years after their initial creation. Objects created more than 3 years ago are accessed very infrequently (less than once a year). You need to configure object storage while ensuring that storage cost is optimized. What should you do? (Choose two.)
Your service adds text to images that it reads from Cloud Storage. During busy times of the year, requests to
Cloud Storage fail with an HTTP 429 "Too Many Requests" status code.
How should you handle this error?
You are in the final stage of migrating an on-premises data center to Google Cloud. You are quickly approaching your deadline, and discover that a web API is running on a server slated for decommissioning. You need to recommend a solution to modernize this API while migrating to Google Cloud. The modernized web API must meet the following requirements:
• Autoscales during high traffic periods at the end of each month
• Written in Python 3.x
• Developers must be able to rapidly deploy new versions in response to frequent code changes
You want to minimize cost, effort, and operational overhead of this migration. What should you do?
You are configuring a continuous integration pipeline using Cloud Build to automate the deployment of new container images to Google Kubernetes Engine (GKE). The pipeline builds the application from its source code, runs unit and integration tests in separate steps, and pushes the container to Container Registry. The application runs on a Python web server.
The Dockerfile is as follows:
FROM python:3.7-alpine -
COPY . /app -
WORKDIR /app -
RUN pip install -r requirements.txt
CMD [ "gunicorn", "-w 4", "main:app" ]
You notice that Cloud Build runs are taking longer than expected to complete. You want to decrease the build time. What should you do? (Choose two.)
Your operations team has asked you to create a script that lists the Cloud Bigtable, Memorystore, and Cloud SQL databases running within a project. The script should allow users to submit a filter expression to limit the results presented. How should you retrieve the data?
You have decided to migrate your Compute Engine application to Google Kubernetes Engine. You need to build a container image and push it to Artifact Registry using Cloud Build. What should you do? (Choose two.)
A)
Run gcloud builds submit in the directory that contains the application source code.
B)
Run gcloud run deploy app-name --image gcr.io/$PROJECT_ID/app-name in the directory that contains the application source code.
C)
Run gcloud container images add-tag gcr.io/$PROJECT_ID/app-name gcr.io/$PROJECT_ID/app-name:latest in the directory that contains the application source code.
D)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:

E)
In the application source directory, create a file named cloudbuild.yaml that contains the following contents:
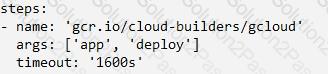
You recently deployed your application in Google Kubernetes Engine, and now need to release a new version of your application. You need the ability to instantly roll back to the previous version in case there are issues with the new version. Which deployment model should you use?
Your team has created an application that is hosted on a Google Kubernetes Engine (GKE) cluster You need to connect the application to a legacy REST service that is deployed in two GKE clusters in two different regions. You want to connect your application to the legacy service in a way that is resilient and requires the fewest number of steps You also want to be able to run probe-based health checks on the legacy service on a separate port How should you set up the connection?
You are developing a web application that will be accessible over both HTTP and HTTPS and will run on Compute Engine instances. On occasion, you will need to SSH from your remote laptop into one of the Compute Engine instances to conduct maintenance on the app. How should you configure the instances while following Google-recommended best practices?
You are parsing a log file that contains three columns: a timestamp, an account number (a string), and a
transaction amount (a number). You want to calculate the sum of all transaction amounts for each unique
account number efficiently.
Which data structure should you use?
Users are complaining that your Cloud Run-hosted website responds too slowly during traffic spikes. You want to provide a better user experience during traffic peaks. What should you do?
Total 265 questions
