Microsoft DP-700 Practice Test Questions Answers
Exam Code: DP-700
(Updated 129 Q&As with Explanation)
Exam Name: Implementing Data Engineering Solutions Using Microsoft Fabric
Last Update: 29-Jun-2026
Demo:
Download Demo
Questions Include:
DP-700 Overview
Top Vendors














Reliable Solution To Pass DP-700 Microsoft Certified: Fabric Data Engineer Associate Certification Test
Our easy to learn DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric questions and answers will prove the best help for every candidate of Microsoft DP-700 exam and will award a 100% guaranteed success!
Why DP-700 Candidates Put Solution2Pass First?
Solution2Pass is ranked amongst the top DP-700 study material providers for almost all popular Microsoft Certified: Fabric Data Engineer Associate certification tests. Our prime concern is our clients’ satisfaction and our growing clientele is the best evidence on our commitment. You never feel frustrated preparing with Solution2Pass’s Implementing Data Engineering Solutions Using Microsoft Fabric guide and DP-700 dumps. Choose what best fits with needs. We assure you of an exceptional DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric study experience that you ever desired.
A Guaranteed Microsoft DP-700 Practice Test Exam PDF
Keeping in view the time constraints of the IT professionals, our experts have devised a set of immensely useful Microsoft DP-700 braindumps that are packed with the vitally important information. These Microsoft DP-700 dumps are formatted in easy DP-700 questions and answers in simple English so that all candidates are equally benefited with them. They won’t take much time to grasp all the Microsoft DP-700 questions and you will learn all the important portions of the DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric syllabus.
Most Reliable Microsoft DP-700 Passing Test Questions Answers
A free content may be an attraction for most of you but usually such offers are just to attract people to clicking pages instead of getting something worthwhile. You need not surfing for online courses free or otherwise to equip yourself to pass DP-700 exam and waste your time and money. We offer you the most reliable Microsoft DP-700 content in an affordable price with 100% Microsoft DP-700 passing guarantee. You can take back your money if our product does not help you in gaining an outstanding DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric exam success. Moreover, the registered clients can enjoy special discount code for buying our products.
Microsoft DP-700 Microsoft Certified: Fabric Data Engineer Associate Practice Exam Questions and Answers
For getting a command on the real Microsoft DP-700 exam format, you can try our DP-700 exam testing engine and solve as many DP-700 practice questions and answers as you can. These Microsoft DP-700 practice exams will enhance your examination ability and will impart you confidence to answer all queries in the Microsoft DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric actual test. They are also helpful in revising your learning and consolidate it as well. Our Implementing Data Engineering Solutions Using Microsoft Fabric tests are more useful than the VCE files offered by various vendors. The reason is that most of such files are difficult to understand by the non-native candidates. Secondly, they are far more expensive than the content offered by us. Read the reviews of our worthy clients and know how wonderful our Implementing Data Engineering Solutions Using Microsoft Fabric dumps, DP-700 study guide and DP-700 Implementing Data Engineering Solutions Using Microsoft Fabric practice exams proved helpful for them in passing DP-700 exam.


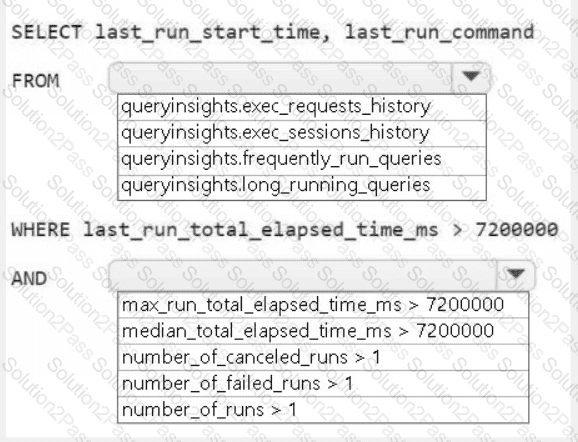
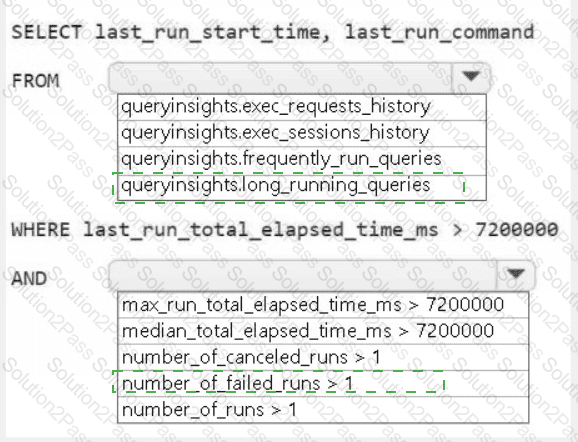
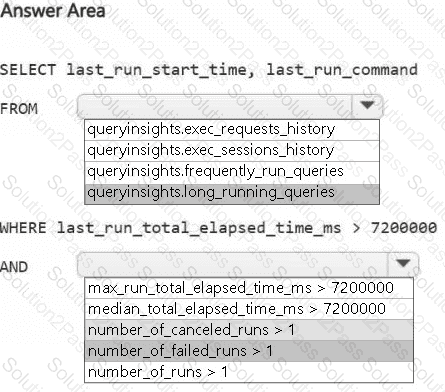 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated