DP-300 Microsoft Administering Relational Databases on Microsoft Azure Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Microsoft DP-300 Administering Relational Databases on Microsoft Azure certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
You need to implement statistics maintenance for SalesSQLDb1. The solution must meet the technical requirements.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
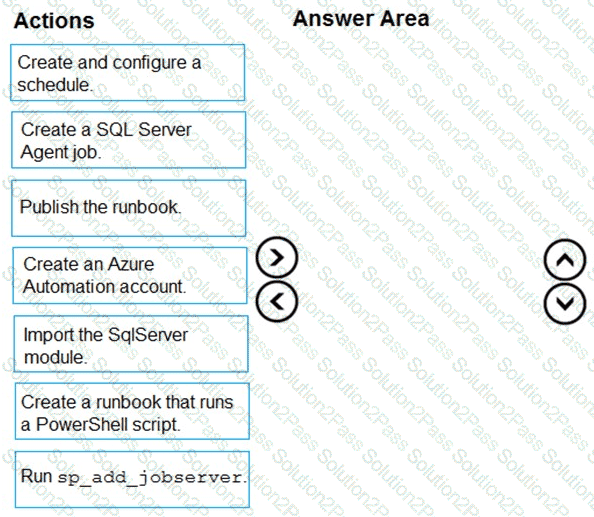
The Answer Is:
Explanation:

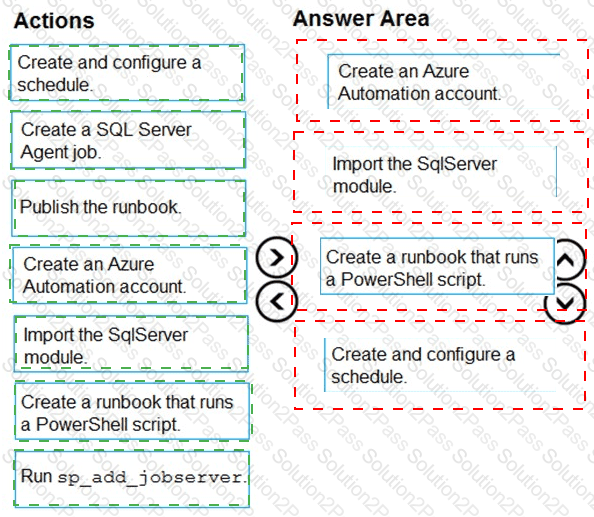
Automating Azure SQL DB index and statistics maintenance using Azure Automation:
1. Create Azure automation account (Step 1)
2. Import SQLServer module (Step 2)
3. Add Credentials to access SQL DB
This will use secure way to hold login name and password that will be used to access Azure SQL DB
4. Add a runbook to run the maintenance (Step 3)
Steps:
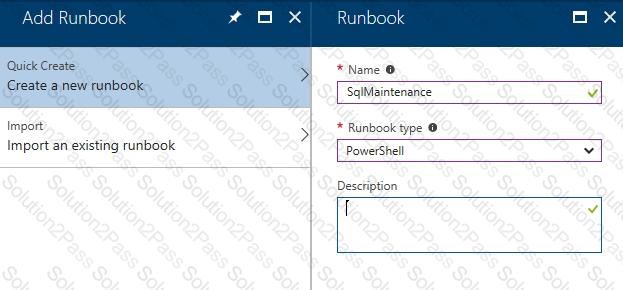
1. Click on " runbooks " at the left panel and then click " add a runbook "
2. Choose " create a new runbook " and then give it a name and choose " Powershell " as the type of the runbook and then click on " create "
5. Schedule task (Step 4)
Steps:
1. Click on Schedules
2. Click on " Add a schedule " and follow the instructions to choose existing schedule or create a new schedule.
What should you use to migrate the PostgreSQL database?
Azure Data Box
AzCopy
Azure Database Migration Service
Azure Site Recovery
The Answer Is:
CExplanation:
Task 1
In an Azure SQL database named db1, you need to enable page compression on the PK_SalesOrderHeader_SalesOrderlD clustered index of the SalesLT.SalesOrderHeader table.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To enable page compression on the PK_SalesOrderHeader_SalesOrderlD clustered index of the SalesLT.SalesOrderHeader table in db1, you can use the following Transact-SQL script:
-- Connect to the Azure SQL database named db1
USE db1;
GO
-- Enable page compression on the clustered index
ALTER INDEX PK_SalesOrderHeader_SalesOrderlD ON SalesLT.SalesOrderHeader
REBUILD WITH (DATA_COMPRESSION = PAGE);
GO
This script will rebuild the clustered index with page compression, which can reduce the storage space and improve the query performance
The script solution consists of three parts:
The first part is USE db1; GO. This part connects to the Azure SQL database named db1, where the SalesLT.SalesOrderHeader table is located. The GO command separates the batches of Transact-SQL statements and sends them to the server.
The second part is ALTER INDEX PK_SalesOrderHeader_SalesOrderlD ON SalesLT.SalesOrderHeader REBUILD WITH (DATA_COMPRESSION = PAGE); GO. This part enables page compression on the clustered index named PK_SalesOrderHeader_SalesOrderlD, which is defined on the SalesLT.SalesOrderHeader table. The ALTER INDEX statement modifies the properties of an existing index. The REBUILD option rebuilds the index from scratch, which is required to change the compression setting. The DATA_COMPRESSION = PAGE option specifies that page compression is applied to the index, which means that both row and prefix compression are used. Page compression can reduce the storage space and improve the query performance by compressing the data at the page level. The GO command ends the batch of statements.
The third part is optional, but it can be useful to verify the compression status of the index. It is SELECT name, index_id, data_compression_desc FROM sys.indexes WHERE object_id = OBJECT_ID( ' SalesLT.SalesOrderHeader ' );. This part queries the sys.indexes catalog view, which contains information about the indexes in the database. The SELECT statement returns the name, index_id, and data_compression_desc columns for the indexes that belong to the SalesLT.SalesOrderHeader table. The OBJECT_ID function returns the object identification number for the table name. The data_compression_desc column shows the compression type of the index, which should be PAGE for the clustered index after the script is executed.
These are the steps of the script solution for enabling page compression on the clustered index of the SalesLT.SalesOrderHeader table in db1.
Task 11
You have a legacy application written for Microsoft SQL Server 2012. The application will be the only application that accesses db1 You need to ensure that db1 is compatible with all the features and syntax of SQL Server 2012.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To ensure that db1 is compatible with all the features and syntax of SQL Server 2012, you need to set the compatibility level of the database to 110, which is the compatibility level for SQL Server 20121. The compatibility level affects the behavior of certain Transact-SQL statements and features, and determines how the database engine interprets the SQL code2.
You can set the compatibility level of db1 by using the Azure portal or Transact-SQL statements. Here are the steps for both methods:
Using the Azure portal:
Go to the Azure portal and select your Azure SQL Database server that hosts db1.
Select the database db1 and click on Query Performance Insight in the left menu.
Click on Configure Query Store and select 110 from the Compatibility level dropdown list.
Click on Save to apply the change.
Using Transact-SQL statements:
Connect to db1 using SQL Server Management Studio, Azure Data Studio, or any other tool that supports Transact-SQL statements.
Open a new query window and run the following command: ALTER DATABASE db1 SET COMPATIBILITY_LEVEL = 110; GO
This command will set the compatibility level of db1 to 110, which is equivalent to SQL Server 2012.
These are the steps to set the compatibility level of db1 to 110.
Task 7
You plan to create an automation runbook that will create database users in db1 from Azure AD identities. You need to configure sq1370O6895 to support the creation of new database users.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To configure sq1370O6895 to support the creation of new database users from Azure AD identities, you need to do the following steps:
Set up a Microsoft Entra tenant and associate it with your Azure subscription. You can use the Microsoft Entra portal or the Azure portal to create and manage your Microsoft Entra users and groups12.
Configure a Microsoft Entra admin for sq1370O6895. You can use the Azure portal or the Azure CLI to set a Microsoft Entra user as the admin for the server34. The Microsoft Entra admin can create other database users from Microsoft Entra identities5.
Connect to db1 using the Microsoft Entra admin account and run the following Transact-SQL statement to create a new database user from a Microsoft Entra identity: CREATE USER [Microsoft Entra user name] FROM EXTERNAL PROVIDER;6 You can replace the Microsoft Entra user name with the name of the user or group that you want to create in the database.
Grant the appropriate permissions to the new database user by adding them to a database role or granting them specific privileges. For example, you can run the following Transact-SQL statement to add the new user to the db_datareader role: ALTER ROLE db_datareader ADD MEMBER [Microsoft Entra user name];
These are the steps to configure sq1370O6895 to support the creation of new database users from Azure AD identities.
Task 4
You need to enable change data capture (CDC) for db1.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To enable change data capture (CDC) for db1, you need to run the stored procedure sys.sp_cdc_enable_db in the database context. CDC is a feature that records activity on a database when tables and rows have been modified1. CDC can be used for various scenarios, such as data synchronization, auditing, or ETL processes2.
Here are the steps to enable CDC for db1:
Connect to db1 using SQL Server Management Studio, Azure Data Studio, or any other tool that supports Transact-SQL statements.
Open a new query window and run the following command: EXEC sys.sp_cdc_enable_db; GO
This command will enable CDC for the database and create the cdc schema, cdc user, metadata tables, and other system objects for the database3.
To verify that CDC is enabled for db1, you can query the is_cdc_enabled column in the sys.databases catalog view. The value should be 1 for db1.
These are the steps to enable CDC for db1
Task 7
You need to capture the following information for all the databases on sql60l 52867;
• Queries to the databases
• Users that executed the queries
The captured information must be stored in sa60152867.
You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Enable Azure SQL Auditing at the server level on the Azure SQL logical server:
sql60152867
and configure the audit destination as the Azure Storage account:
sa60152867
This is the correct solution because the task says all databases on sql60152867. Database-level auditing would only apply to one database. Server-level auditing applies to all existing and newly created databases on the logical server. Microsoft states that server auditing policies apply to all existing and newly created databases on the server. The default auditing policy includes BATCH_COMPLETED_GROUP, which audits queries and stored procedures executed against the database, plus successful and failed authentication events.
Azure Portal Method — Recommended for Simulation
Step 1: Open the Azure SQL logical server
Sign in to the Azure portal.
Search for:
SQL servers
Open the SQL logical server named:
sql60152867
Be careful with the name. In your prompt, it appears as sql60l 52867, but the earlier tasks strongly indicate the real server name is probably:
sql60152867
Use the SQL logical server that hosts the databases, not a single SQL database.
Step 2: Open Auditing
On the SQL server page:
In the left menu, go to Security.
Select Auditing.
Microsoft’s setup path is to navigate to Auditing under the Security heading in either the SQL database or SQL server pane. For this task, you must use the SQL server pane because the requirement covers all databases.
Step 3: Enable server-level auditing
Set:
Enable Azure SQL Auditing = On
or:
Auditing = On
depending on the portal wording.
This enables the server-level audit policy.
Step 4: Select Storage as the audit destination
Under Audit log destination, select:
Storage
Then choose the storage account:
sa60152867
Microsoft states that Azure SQL auditing can write database events to an Azure storage account, Log Analytics workspace, or Event Hubs. For this simulation, the destination must be the storage account sa60152867, so do not choose Log Analytics or Event Hub unless the task separately asks for them.
Step 5: Configure storage authentication
If the portal asks for authentication type, use one of these depending on what is available in the lab:
Option
Use when
Managed Identity
Preferred if available
Storage access keys
Use if the lab expects the older/default storage-key method
Microsoft recommends managed identity for storage authentication because storage access keys are a security risk. However, many exam simulations still accept the default storage-key flow as long as the audit destination is correctly set to the required storage account.
Step 6: Leave default audit action groups enabled
Do not remove the default audit action groups.
The default Azure SQL auditing policy includes:
BATCH_COMPLETED_GROUP
SUCCESSFUL_DATABASE_AUTHENTICATION_GROUP
FAILED_DATABASE_AUTHENTICATION_GROUP
BATCH_COMPLETED_GROUP is the key one here because it captures completed T-SQL batches, meaning the queries executed against the databases. Authentication and principal fields identify the login/user context. Microsoft states that the default auditing policy audits all queries and stored procedures executed against the database, plus successful and failed logins.
Step 7: Save the auditing configuration
Select:
Save
Wait for the portal notification that the auditing settings were saved successfully.
That completes the required configuration.
Verification
Verify from the Azure portal
Open the SQL server:
sql60152867
Go to:
Security > Auditing
Confirm:
Auditing: On
Destination: Storage
Storage account: sa60152867
Scope: Server-level
Verify storage output
After users execute queries, audit files should appear in the storage account.
Open storage account:
sa60152867
Go to Containers.
Open:
sqldbauditlogs
Azure SQL audit logs written to Azure Storage are stored in a container named sqldbauditlogs. Audit logs are written as .xel files and can be opened with SQL Server Management Studio.
What Information Is Captured?
The audit log includes the exact fields needed for this task.
Required information
Audit log field
Query executed
statement / statement_s
Database name
database_name / database_name_s
User context
database_principal_name / database_principal_name_s
Login context
server_principal_name / server_principal_name_s
Session principal
session_server_principal_name / session_server_principal_name_s
Time of execution
event_time / event_time_t
Client IP
client_ip / client_ip_s
Microsoft’s audit log format documents statement as the T-SQL statement that was executed, database_principal_name as the database user context, and server_principal_name as the current login.
SSMS Method — Viewing the Audit Logs
SSMS is not the main tool to enable Azure SQL auditing in this simulation, but it can be used to read the .xel audit files after they are written.
Step 1: Download or access the .xel files
From the storage account:
sa60152867 > Containers > sqldbauditlogs
Download the .xel audit file, or access it through supported tooling.
Step 2: Open the audit file in SSMS
Open SQL Server Management Studio.
Go to:
File > Open > File
Select the .xel audit file.
Review fields such as:
statement
database_principal_name
server_principal_name
database_name
event_time
client_ip
This verifies that the queries and the users that executed them are being captured.
Azure CLI Method
Use this only if Cloud Shell is available and you know the resource group names.
az sql server audit-policy update \
--resource-group < resource-group-name > \
--name sql60152867 \
--state Enabled \
--storage-account sa60152867
Depending on the environment, you may also need to specify the storage endpoint and access key, or use managed identity configuration. In the portal simulation, the UI normally handles this for you.
PowerShell Method
Use this if Azure PowerShell is available.
Set-AzSqlServerAudit `
-ResourceGroupName " < resource-group-name > " `
-ServerName " sql60152867 " `
-BlobStorageTargetState Enabled `
-StorageAccountResourceId " /subscriptions/ < subscription-id > /resourceGroups/ < storage-rg > /providers/Microsoft.Storage/storageAccounts/sa60152867 "
This configures auditing at the server level, which is the correct scope for all databases.
Final Exam-Lab Action
Configure this in the Azure portal:
SQL server: sql60152867
Security > Auditing
Auditing: On
Audit destination: Storage
Storage account: sa60152867
Default audit action groups: Enabled
Save
That captures queries and the users who executed them for all databases on the SQL logical server and stores the audit records in sa60152867.
Task 2
You need to configure your user account as the Azure AD admin for the server named sql3700689S.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To configure your user account as the Azure AD admin for the server named sql3700689S, you can use the Azure portal or the Azure CLI. Here are the steps for both methods:
Using the Azure portal:
Go to the Azure portal and select SQL Server – Azure Arc.
Select the server named sql3700689S and click on Active Directory admin.
Click on Set admin and choose your user account from the list of Azure AD users.
Click on Select and then Save to confirm the change.
You can verify the Azure AD admin by clicking on Active Directory admin again and checking the current admin.
Using the Azure CLI:
Install the Azure CLI and log in with your Azure account.
Run the following command to get the object ID of your user account: az ad user show --id < your-user-name > --query objectId -o tsv
Run the following command to set your user account as the Azure AD admin for the server: az sql server ad-admin create --server sql3700689S --object-id < your-object-id > --display-name < your-user-name >
You can verify the Azure AD admin by running the following command: az sql server ad-admin show --server sql3700689S
These are the steps to configure your user account as the Azure AD admin for the server named sql3700689S.
Task 10
You need to protect all the databases on sql37006S95 from SQL injection attacks.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
SQL injection attacks are a type of cyberattack that exploit a vulnerability in the application code that interacts with the database. An attacker can inject malicious SQL statements into the user input, such as a form field or a URL parameter, and execute them on the database server, resulting in data theft, corruption, or unauthorized access1.
To protect all the databases on sql37006S95 from SQL injection attacks, you need to follow some best practices for securing your application and database layers. Here are some of the recommended steps:
Use parameterized queries or stored procedures to separate the SQL code from the user input. This will prevent the user input from being interpreted as part of the SQL statement and avoid SQL injection23.
Validate and sanitize the user input before passing it to the database. This will ensure that the input conforms to the expected format and type, and remove any potentially harmful characters or keywords4.
Implement least privilege access for the database users and roles. This will limit the permissions and actions that the application can perform on the database, and reduce the impact of a successful SQL injection attack5.
Enable Advanced Threat Protection for Azure SQL Database. This is a feature that detects and alerts you of anomalous activities and potential threats on your database, such as SQL injection, brute force attacks, or unusual access patterns. You can configure the alert settings and notifications using the Azure portal or PowerShell.
These are some of the steps to protect all the databases on sql37006S95 from SQL injection attacks.
Task 6
You need to ensure that you can connect to db1 by using a private IP address on a virtual network named VNET1 You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Create an Azure Private Endpoint for the Azure SQL logical server that hosts db1, place the private endpoint in VNET1, and integrate it with the private DNS zone:
privatelink.database.windows.net
This is the correct solution because Azure SQL Database is a PaaS service. You do not assign a private IP directly to db1. Instead, Azure creates a private endpoint network interface in the virtual network. That private endpoint receives a private IP address from a subnet in VNET1, and clients in VNET1 use that private IP path to reach the SQL server. Microsoft defines a private endpoint as a network interface that uses a private IP address from your virtual network to connect privately to a Private Link resource such as Azure SQL Database.
Azure Portal Method — Recommended for Simulation
Step 1: Identify the SQL logical server that hosts db1
Sign in to the Azure portal.
Search for SQL databases.
Open db1.
On the database overview page, identify the Server name.
The private endpoint is created for the Azure SQL logical server, not for the database object alone. For Azure SQL Database, the Private Link resource type is:
Microsoft.Sql/servers
and the target subresource is:
sqlServer
Microsoft lists Azure SQL Database private endpoint DNS configuration under Microsoft.Sql/servers with subresource sqlServer.
Step 2: Open the SQL server networking page
Open the Azure SQL logical server that hosts db1.
In the left menu, go to:
Security > Networking
Select the Private access tab.
Select Create a private endpoint.
Microsoft’s Azure SQL private endpoint workflow is performed from the SQL server resource under Networking > Private access, where you can create or manage private endpoint connections.
Step 3: Configure the private endpoint basics
On the Create private endpoint page:
Setting
Value
Subscription
Use the lab subscription
Resource group
Use the lab resource group
Name
pe-db1-sql
Region
Same region as VNET1, if possible
The name is not exam-critical. The critical part is that the endpoint is associated with VNET1 and the SQL server that hosts db1.
Step 4: Configure the target resource
On the Resource tab, configure:
Setting
Value
Connection method
Connect to an Azure resource in my directory
Resource type
Microsoft.Sql/servers
Resource
SQL logical server that hosts db1
Target sub-resource
sqlServer
Do not choose storage, VM, managed instance, or any unrelated resource type. This is Azure SQL Database, so the target subresource must be sqlServer.
Step 5: Configure VNET1 and subnet
On the Virtual Network tab:
Setting
Value
Virtual network
VNET1
Subnet
Select an available subnet in VNET1
Private IP configuration
Dynamic is fine unless the lab requires static
Azure will create a network interface for the private endpoint and assign it a private IP address from the selected subnet. Microsoft notes that the network interface page for the private endpoint shows the private IP address assigned to the private endpoint connection.
Step 6: Configure private DNS integration
On the DNS tab:
Enable private DNS zone integration.
Use or create the private DNS zone:
privatelink.database.windows.net
Link the private DNS zone to:
VNET1
This is not optional in a clean exam solution. Without DNS integration, clients may still resolve the SQL server name to the public endpoint instead of the private endpoint. Microsoft states that DNS is critical because it resolves the private endpoint IP address, and for Azure SQL Database the recommended private DNS zone is privatelink.database.windows.net.
Step 7: Review and create
Select Review + create.
Confirm:
Resource: SQL logical server hosting db1
Target subresource: sqlServer
Virtual network: VNET1
Private DNS zone: privatelink.database.windows.net
Select Create.
After deployment, the SQL server will have a private endpoint connection associated with VNET1.
Step 8: Approve the private endpoint connection if required
In most same-directory deployments, approval may be automatic. If approval is pending:
Open the SQL logical server.
Go to:
Networking > Private access
Select the pending private endpoint connection.
Select Approve.
Microsoft documents that SQL administrators can approve or reject private endpoint connections from the SQL server private access page.
Step 9: Optional but recommended — Disable public network access
The task only says you need to connect by private IP from VNET1. It does not explicitly say to block public access. But if the exam expects private-only access, then disable public access after the private endpoint works.
On the SQL logical server:
Go to:
Security > Networking > Public access
Set Public network access to:
Disabled
or select:
Deny public network access
Save.
Be careful: Microsoft states that adding a private endpoint does not automatically block public routing to the logical server. Public access must be denied separately if you want private-only access.
How to Connect from SSMS
You should connect from a machine that is inside VNET1, such as an Azure VM joined to VNET1.
Step 1: Test DNS from a VM in VNET1
From a VM in VNET1, run:
nslookup < sql-server-name > .database.windows.net
Expected result: the name should resolve through the private endpoint path and return a private IP address from VNET1’s address space.
Microsoft explains that connection URLs do not change; DNS resolution is overridden so the existing service FQDN resolves to the private endpoint private IP address.
Step 2: Connect with SSMS
In SSMS, connect using the normal Azure SQL server name:
< sql-server-name > .database.windows.net
Then select database:
db1
Use normal SQL authentication or Microsoft Entra authentication.
Do not type the raw private IP address into SSMS unless the lab specifically forces it. For Azure SQL, the correct operational pattern is to connect to the SQL server FQDN and allow private DNS to resolve that FQDN to the private endpoint IP. Direct IP connection can cause TLS/certificate name problems because the server certificate matches the DNS name, not the private IP.
Verification
The task is complete when all of these are true:
Private endpoint exists for the SQL logical server hosting db1.
Target subresource is sqlServer.
The private endpoint is deployed into VNET1.
A private IP address is assigned to the private endpoint NIC.
Private DNS zone privatelink.database.windows.net exists.
The private DNS zone is linked to VNET1.
The SQL server FQDN resolves to the private endpoint private IP from inside VNET1.
SSMS can connect to db1 from a VM or client connected to VNET1.
Final Exam-Lab Action
Use the Azure portal and configure:
SQL server hosting db1
> Networking
> Private access
> Create private endpoint
Resource type: Microsoft.Sql/servers
Target subresource: sqlServer
Virtual network: VNET1
Private DNS zone: privatelink.database.windows.net
Then connect from a VM or client in VNET1 using:
< sql-server-name > .database.windows.net
That is the correct way to ensure db1 is reachable through a private IP address on VNET1.
Task 6
You need to ensure that any enhancements made to the Query Optimizer through patches are available to dbl and db2 on sql37006895.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To ensure that any enhancements made to the Query Optimizer through patches are available to dbl and db2 on sql37006895, you need to enable the query optimizer hotfixes option for each database. This option allows you to use the latest query optimization improvements that are not enabled by default1. You can enable this option by using the ALTER DATABASE SCOPED CONFIGURATION statement2.
Here are the steps to enable the query optimizer hotfixes option for dbl and db2 on sql37006895:
Connect to sql37006895 using SQL Server Management Studio, Azure Data Studio, or any other tool that supports Transact-SQL statements.
Open a new query window and run the following commands for each database:
-- Switch to the database context
USE dbl;
GO
-- Enable the query optimizer hotfixes option
ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES = ON;
GO
Repeat the same commands for db2, replacing dbl with db2 in the USE statement.
To verify that the query optimizer hotfixes option is enabled for each database, you can query the sys.database_scoped_configurations catalog view. The value of the query_optimizer_hotfixes column should be 1 for both databases.
These are the steps to enable the query optimizer hotfixes option for dbl and db2 on sql37006895.
Task 9
You need to generate an email alert to admin@contoso.com when CPU percentage utilization for db1 is higher than average.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
To generate an email alert to admin@contoso.com when CPU percentage utilization for db1 is higher than average, you can use the Azure portal to create an alert rule based on the CPU percentage metric. Here are the steps to do that:
Go to the Azure portal and select your Azure SQL Database server that hosts db1.
Select Alerts in the Monitoring section and click on New alert rule.
In the Condition section, click Add and select the CPU percentage metric.
In the Configure signal logic page, set the threshold type to Dynamic. This will compare the current metric value to the historical average and trigger the alert when it deviates significantly1.
Set the operator to Greater than, the aggregation type to Average, the aggregation granularity to 1 minute, and the frequency of evaluation to 5 minutes.
Click Done to save the condition.
In the Action group section, click Create and enter a name and a short name for the action group.
In the Notifications section, click Add and select Email/SMS message/Push/Voice.
Enter admin@contoso.com in the Email field and click OK.
Click OK to save the action group.
In the Alert rule details section, enter a name and a description for the alert rule, choose a severity level, and make sure the rule is enabled.
Click Create alert rule to create the alert rule.
This alert rule will send an email to admin@contoso.com when the CPU percentage utilization for db1 is higher than average. You can also add other actions to the alert rule, such as calling a webhook or running an automation script
Task 3
You need to prevent users from accidentally deleting db1 from the Azure portal. You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Apply an Azure Resource Manager Delete lock / CanNotDelete lock directly to the Azure SQL database resource db1.
Microsoft states that Azure resource locks can be applied at subscription, resource group, or resource scope to protect resources from accidental deletion or modification. In the Azure portal, the lock types are shown as Delete and Read-only; in CLI/PowerShell, they are called CanNotDelete and ReadOnly. A CanNotDelete/Delete lock allows users to read and modify the resource, but prevents deletion.
Azure Portal Method — Recommended for Simulation
Step 1: Open the database resource
Sign in to the Azure portal.
In the search bar, search for SQL databases.
Select the database named db1.
Make sure you select the database resource itself, not only the SQL logical server.
Step 2: Open Locks
In the left menu of db1, scroll to Settings.
Select Locks.
Select Add.
Step 3: Create the delete lock
Configure the lock as follows:
Setting
Value
Lock name
PreventDelete-db1
Lock type
Delete
Notes
Prevent accidental deletion of db1
Then select OK or Save.
In the portal, choose Delete, not Read-only. A Read-only lock is too restrictive because it can block management updates. For this task, the requirement is only to stop accidental deletion, so Delete / CanNotDelete is the correct lock type. Microsoft confirms that CanNotDelete prevents deletion but still permits reading and modifying the resource.
Step 4: Verify the lock
Stay on the db1 database page.
Go back to Locks.
Confirm the lock exists with:
Name: PreventDelete-db1
Lock type: Delete
The task is complete once db1 has a Delete lock applied.
PowerShell Method
Use this if the lab provides Azure PowerShell.
New-AzResourceLock `
-LockLevel CanNotDelete `
-LockName " PreventDelete-db1 " `
-LockNotes " Prevent accidental deletion of db1 " `
-ResourceGroupName " < resource-group-name > " `
-ResourceName " < sql-server-name > /db1 " `
-ResourceType " Microsoft.Sql/servers/databases "
Microsoft’s New-AzResourceLock documentation includes an Azure SQL Database example using resource type Microsoft.Sql/servers/databases and resource name format serverName/databaseName.
Example format:
New-AzResourceLock `
-LockLevel CanNotDelete `
-LockName " PreventDelete-db1 " `
-LockNotes " Prevent accidental deletion of db1 " `
-ResourceGroupName " RG1 " `
-ResourceName " sql60152867/db1 " `
-ResourceType " Microsoft.Sql/servers/databases "
Replace RG1 and sql60152867 with the actual resource group and SQL logical server that hosts db1.
Azure CLI Method
Use Azure CLI only if the lab gives Cloud Shell and you know the full resource ID.
First get the database resource ID:
az sql db show \
--resource-group < resource-group-name > \
--server < sql-server-name > \
--name db1 \
--query id \
--output tsv
Then create the lock:
az resource lock create \
--name PreventDelete-db1 \
--lock-type CanNotDelete \
--resource < database-resource-id > \
--notes " Prevent accidental deletion of db1 "
Azure CLI supports resource-level lock creation with --lock-type CanNotDelete or ReadOnly.
SSMS / T-SQL Clarification
SSMS is not the correct tool for this task.
A delete lock is an Azure Resource Manager control-plane setting, not a SQL data-plane setting. SQL Server Management Studio can manage database objects and run T-SQL, but it cannot create Azure portal deletion protection locks for an Azure SQL Database.
Task 1
You need to implement a disaster recovery solution by using active geo replication for an Azure Azure SQL database named db1. The replica must be in the East US or East US 2 Azure region on a server named sql60152867-dr.database.windows.net. You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Requirement: Configure active geo-replication for Azure SQL Database db1. The geo-replica must be created in East US or East US 2 on the logical Azure SQL server:
sql60152867-dr.database.windows.net
The important point: in Azure SQL, the logical server name used in portal/T-SQL is usually:
sql60152867-dr
not the full FQDN.
Microsoft states that active geo-replication is configured per database, and a geo-secondary is created for an existing Azure SQL Database. After creation and seeding, changes from the primary are replicated asynchronously to the secondary.
Method 1 — Azure Portal Method
This is the safest method for the simulation if the portal is available.
Step 1: Open the primary database
Sign in to the Azure portal.
Search for SQL databases.
Select the database named db1.
Confirm you are looking at the primary database, not an existing secondary.
Step 2: Open the Replicas blade
In the left menu of the db1 database page, scroll to Data management.
Select Replicas.
Select Create replica.
Microsoft’s portal workflow is: open the database, go to Data management > Replicas, and choose Create replica.
Step 3: Configure the geo-secondary replica
On the Create SQL Database replica page, configure the target like this:
Setting
Value
Database
db1
Replica type
Geo replica / Active geo-replication
Target server
sql60152867-dr
Region
East US or East US 2
Database name
db1
Compute + storage
Keep same or compatible with primary
Elastic pool
Only choose this if the lab specifically requires an elastic pool
Do not create a failover group unless the task asks for one. This task says active geo replication, so configure a database-level geo-replica, not a failover group. Microsoft explicitly separates active geo-replication from failover groups and notes that active geo-replication is configured per database.
Step 4: Review and create
Select Review + create.
Confirm the target server is:
sql60152867-dr
Confirm the region is either:
East US
or
East US 2
Select Create.
Azure will create the secondary database and begin the seeding process. Microsoft notes that the secondary database has the same name as the primary by default and begins replication after it is created and seeded.
Step 5: Verify replication
After deployment completes:
Go back to the primary database db1.
Open Replicas again.
Under Geo replicas, confirm that a replica exists on:
sql60152867-dr.database.windows.net
Confirm the replica status is healthy, online, or synchronizing.
You can also open the target SQL server sql60152867-dr and verify that a database named db1 now exists there.
Method 2 — SSMS / T-SQL Method
Use this method if the portal is awkward or the exam simulation expects T-SQL.
Step 1: Allow SSMS connectivity
Before connecting with SSMS:
In Azure portal, open the primary SQL server hosting db1.
Go to Networking or Firewalls and virtual networks.
Add your client IP address.
Repeat this on the secondary server:
sql60152867-dr.database.windows.net
This matters because SSMS must be able to connect to the Azure SQL logical server.
Step 2: Connect to the primary server in SSMS
Open SQL Server Management Studio.
Connect to the primary Azure SQL logical server that hosts db1.
Use SQL admin credentials or Microsoft Entra admin credentials.
In Connection Properties, connect to the database:
master
This is important. For Azure SQL Database geo-replication setup through T-SQL, run the command from the master database on the primary server.
Step 3: Run the active geo-replication command
Run this query:
ALTER DATABASE [db1]
ADD SECONDARY ON SERVER [sql60152867-dr]
WITH (ALLOW_CONNECTIONS = ALL);
Microsoft documents that ALTER DATABASE ... ADD SECONDARY ON SERVER creates a secondary database for an existing Azure SQL Database and starts data replication. The official example also uses WITH (ALLOW_CONNECTIONS = ALL) to create a readable geo-secondary.
Step 4: Verify the replication link
Still connected to the primary server, run:
SELECT *
FROM sys.geo_replication_links;
Or use:
SELECT *
FROM sys.dm_geo_replication_link_status;
Microsoft lists sys.geo_replication_links and sys.dm_geo_replication_link_status as views used to return information about existing replication links and replication status.
Optional PowerShell Method
Only use this if the lab gives you Cloud Shell or PowerShell access.
New-AzSqlDatabaseSecondary `
-ResourceGroupName " < PrimaryResourceGroupName > " `
-ServerName " < PrimaryServerName > " `
-DatabaseName " db1 " `
-PartnerResourceGroupName " < SecondaryResourceGroupName > " `
-PartnerServerName " sql60152867-dr " `
-PartnerDatabaseName " db1 "
Microsoft identifies New-AzSqlDatabaseSecondary as the PowerShell cmdlet that creates a secondary database for an existing Azure SQL Database and starts replication.
Final Answer / What You Must Achieve
The task is complete when:
Database db1 still exists on the primary server.
A secondary database named db1 exists on:
sql60152867-dr.database.windows.net
The target server is in East US or East US 2.
The replica appears under db1 > Replicas > Geo replicas.
Replication status is healthy, online, seeding, or synchronizing.
You did not configure a failover group unless separately requested.
Task 2
You need to configure differential backups for the db1 Azure SQL database to be once a day instead of twice day. You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Requirement: Configure differential backups for Azure SQL Database db1 to run once a day instead of twice a day.
Correct setting: Change Differential backup frequency from 12 Hours to 24 Hours.
Azure SQL Database supports differential backup frequency of either 12 hours or 24 hours. A 12-hour frequency means twice per day; a 24-hour frequency means once per day. Microsoft also notes that 24-hour differential backup frequency can increase restore time compared with 12-hour frequency.
Method 1 — Azure Portal Method
This is the best method for the simulation.
Step 1: Open the Azure SQL logical server
Sign in to the Azure portal.
Search for SQL servers.
Open the logical SQL server that hosts database db1.
Do not start from SQL Server Management Studio for this task. The differential backup frequency is an Azure SQL backup policy setting, not a normal T-SQL database setting.
Step 2: Open the Backups page
In the SQL server left menu, select Backups.
Select the Retention policies tab.
Microsoft’s documented portal path is to go to the logical SQL server, select Backups, then select the Retention policies tab.
Step 3: Select database db1
In the list of databases, locate db1.
Select the checkbox next to db1.
Select Configure policies from the action bar.
Step 4: Change the differential backup frequency
In the policy configuration pane:
Find Differential backup frequency.
Change it from:
12 Hours
to:
24 Hours
Leave the PITR retention period unchanged unless the task specifically tells you to change it.
Select Apply or Save.
Microsoft’s documented option is exactly 12 Hours or 24 hours under Differential backup frequency.
Method 2 — Azure CLI Method
Use this if the simulation provides Cloud Shell.
az sql db str-policy set \
--resource-group < resource-group-name > \
--server < server-name > \
--name db1 \
--retention-days < current-retention-days > \
--diffbackup-hours 24
Example:
az sql db str-policy set \
--resource-group RG1 \
--server sql60152867 \
--name db1 \
--retention-days 7 \
--diffbackup-hours 24
Microsoft documents az sql db str-policy set with --diffbackup-hours 24 for changing active database differential backup frequency. Valid values are 12 or 24 hours.
Be careful: do not guess the retention days blindly in a real environment. In the exam lab, use the existing retention value shown in the portal unless the task also asks you to change retention.
Method 3 — PowerShell Method
Use this if Azure PowerShell is available.
Set-AzSqlDatabaseBackupShortTermRetentionPolicy `
-ResourceGroupName " < resource-group-name > " `
-ServerName " < server-name > " `
-DatabaseName " db1 " `
-RetentionDays < current-retention-days > `
-DiffBackupIntervalInHours 24
Microsoft documents Set-AzSqlDatabaseBackupShortTermRetentionPolicy with -DiffBackupIntervalInHours 24 for setting Azure SQL Database differential backup frequency.
SSMS / T-SQL Clarification
For this task, SSMS is not the right tool to change the setting.
There is no normal ALTER DATABASE T-SQL command in Azure SQL Database to change automated differential backup frequency. Microsoft documents this change through:
Azure portal
Azure CLI
PowerShell
REST API
not SSMS/T-SQL.
You may use SSMS only to confirm the database exists and is accessible, but the backup frequency setting must be changed from Azure management tools.
Task 5
You need to generate an email alert for db1 if the average CPU percentage utilization is greater than 50 percent for five minutes sampled at one-minute intervals. The alert must be sent to admin@contoso.com.
You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Create an Azure Monitor metric alert rule on database db1 using the metric:
CPU percentage
Configure the condition as:
Aggregation: Average
Operator: Greater than
Threshold: 50
Aggregation granularity / Period: 1 minute
Frequency of evaluation: 1 minute
Evaluation period / Lookback window: 5 minutes
Action group email: admin@contoso.com
Azure SQL Database exposes CPU percentage as a platform metric, and Azure Monitor metric alerts can send notifications through action groups such as email. Microsoft describes SQL Database alerts as metric-based alerts that can send email when metrics such as CPU usage reach a defined threshold.
Azure Portal Method — Recommended for Simulation
Step 1: Open the db1 Azure SQL database
Sign in to the Azure portal.
Search for SQL databases.
Open the database named:
db1
Do not open the SQL logical server unless the alert needs to apply to all databases. This task is specifically for db1, so the alert scope must be the db1 database resource.
Step 2: Create a new alert rule
From the db1 database page:
In the left menu, select Alerts.
Select Create.
Select Alert rule.
Microsoft’s Azure Monitor workflow allows you to create an alert rule directly from the target resource. When you create it from a resource, the resource is automatically set as the alert scope.
Step 3: Confirm the alert scope
On the alert rule page, confirm the scope is the Azure SQL database:
db1
The resource type should be similar to:
SQL database
Microsoft.Sql/servers/databases
If the scope is the SQL server instead of the database, remove it and select the db1 database resource.
Step 4: Add the alert condition
Under Condition, select Add condition.
Choose the metric:
CPU percentage
Sometimes it appears as:
CPU percent
or metric name:
cpu_percent
For Azure SQL Database, CPU percentage represents CPU consumption toward the database workload limit, expressed as a percentage.
Step 5: Configure the signal logic
Configure the alert logic exactly like this:
Setting
Value
Threshold type
Static
Aggregation type
Average
Operator
Greater than
Threshold value
50
Unit
Percent
Aggregation granularity / Period
1 minute
Frequency of evaluation
1 minute
Evaluation period / Lookback window
5 minutes
This means Azure Monitor evaluates the CPU metric every minute, using one-minute metric samples, and fires the alert only when the average CPU percentage is greater than 50% across the five-minute evaluation window.
Be precise here. The task says:
average CPU percentage utilization is greater than 50 percent for five minutes sampled at one-minute intervals
So the correct choices are:
Average
Greater than 50
Every 1 minute
Over the last 5 minutes
Azure Monitor metric alert rules combine the monitored resource, the metric condition, and action groups that run when the condition is met.
Step 6: Create the email action group
Under Actions, select:
Create action group
Configure the basics:
Setting
Value
Subscription
Use the current subscription
Resource group
Use the lab resource group
Action group name
AG-db1-CPU-Email
Display name
db1CPU
Then go to Notifications.
Add a notification:
Setting
Value
Notification type
Email/SMS message/Push/Voice
Name
EmailAdmin
admin@contoso.com
Select OK, then Review + create, then Create.
Action groups define the notification or automation action that runs when an alert fires. Microsoft documents email as a supported action group notification type.
Step 7: Configure alert rule details
Under Details, configure:
Setting
Value
Severity
2 or 3
Alert rule name
db1 CPU greater than 50 percent
Description
Alert when average CPU percentage for db1 is greater than 50 percent for 5 minutes.
Enable upon creation
Yes
Severity is usually not specified by the task, so any reasonable severity is acceptable. In an exam lab, I would use Severity 2 for CPU performance impact.
Step 8: Review and create
Select Review + create.
Confirm the condition says something equivalent to:
Whenever the average CPU percentage is greater than 50
Confirm the evaluation settings are:
Check every 1 minute
Lookback period 5 minutes
Confirm the action group sends email to:
admin@contoso.com
Select Create.
Verification
After creation:
Open db1.
Go to Alerts.
Select Alert rules.
Confirm the alert rule exists and is enabled.
Open the rule and verify:
Scope: db1
Signal: CPU percentage
Aggregation: Average
Operator: Greater than
Threshold: 50
Evaluation frequency: 1 minute
Window size: 5 minutes
Action group: admin@contoso.com
Azure CLI Method
Use this only if the simulation gives you Cloud Shell.
First get the database resource ID:
az sql db show \
--resource-group < resource-group-name > \
--server < sql-server-name > \
--name db1 \
--query id \
--output tsv
Create the action group:
az monitor action-group create \
--resource-group < resource-group-name > \
--name AG-db1-CPU-Email \
--short-name db1CPU \
--action email EmailAdmin admin@contoso.com
Create the metric alert:
az monitor metrics alert create \
--name " db1 CPU greater than 50 percent " \
--resource-group < resource-group-name > \
--scopes < db1-resource-id > \
--condition " avg cpu_percent > 50 " \
--window-size 5m \
--evaluation-frequency 1m \
--action AG-db1-CPU-Email \
--description " Alert when average CPU percentage for db1 is greater than 50 percent for 5 minutes. "
The metric name commonly used for Azure SQL Database CPU percentage in CLI/ARM contexts is:
cpu_percent
SSMS Clarification
SSMS is not the correct tool for this task.
Do not configure Database Mail. Azure SQL Database does not use SQL Server Agent/Database Mail in the same way as SQL Server on a VM or SQL Managed Instance. This requirement is an Azure Monitor metric alert requirement.
Correct tool:
Azure portal > db1 > Alerts > Create alert rule
Wrong tool:
SSMS Database Mail
Final Exam-Lab Configuration
Use this exact configuration:
Resource: db1
Alert type: Metric alert
Metric: CPU percentage
Aggregation: Average
Operator: Greater than
Threshold: 50
Aggregation granularity: 1 minute
Evaluation frequency: 1 minute
Evaluation period/window: 5 minutes
Action group notification: Email
Email recipient: admin@contoso.com
That completes the task.
You need to design an analytical storage solution for the transactional data. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

The Answer Is:

Explanation:

Box 1: Hash
Scenario:
Ensure that queries joining and filtering sales transaction records based on product ID complete as quickly as possible.
A hash distributed table can deliver the highest query performance for joins and aggregations on large tables.
Box 2: Round-robin
Scenario:
You plan to create a promotional table that will contain a promotion ID. The promotion ID will be associated to a specific product. The product will be identified by a product ID. The table will be approximately 5 GB.
A round-robin table is the most straightforward table to create and delivers fast performance when used as a staging table for loads. These are some scenarios where you should choose Round robin distribution:
When you cannot identify a single key to distribute your data.
If your data doesn’t frequently join with data from other tables.
When there are no obvious keys to join.
Task 9
You need to ensure that when non-administrative users query the SalesLT.Customer table in db1, email addresses are obscured. For example, an email address of alice@contoso.com must appear as aXXX@XXXX.com.
You may need to use SQL Server Management Studio and the Azure portal.
The Answer Is:
See the explanation part for the complete Solution.
Explanation:
Configure Dynamic Data Masking on the email column in:
SalesLT.Customer
The column is normally:
EmailAddress
Use the built-in masking function:
email()
Microsoft documents that Dynamic Data Masking hides sensitive data in query results for nonprivileged users without changing the stored data. The built-in email() masking function exposes the first letter and returns the masked format aXXX@XXXX.com, which exactly matches the requirement.
Method 1 — SSMS / T-SQL Method
This is the fastest and most reliable method.
Step 1: Connect to db1
Open SQL Server Management Studio.
Connect to the Azure SQL logical server that hosts db1.
Open a query window against database:
db1
Step 2: Apply the email mask
Run:
ALTER TABLE [SalesLT].[Customer]
ALTER COLUMN [EmailAddress]
ADD MASKED WITH (FUNCTION = ' email() ' );
This adds a Dynamic Data Masking rule to the EmailAddress column. The actual email address remains stored in the table, but users without permission to view unmasked data will see the masked value. Microsoft’s documented syntax for adding an email mask is ALTER COLUMN Email ADD MASKED WITH (FUNCTION = ' email() ' ).
Step 3: Verify that the column is masked
Run:
SELECT
OBJECT_SCHEMA_NAME(mc.object_id) AS schema_name,
OBJECT_NAME(mc.object_id) AS table_name,
c.name AS column_name,
mc.masking_function
FROM sys.masked_columns AS mc
JOIN sys.columns AS c
ON mc.object_id = c.object_id
AND mc.column_id = c.column_id
WHERE OBJECT_SCHEMA_NAME(mc.object_id) = ' SalesLT '
AND OBJECT_NAME(mc.object_id) = ' Customer '
AND c.name = ' EmailAddress ' ;
Expected result:
schema_name SalesLT
table_name Customer
column_name EmailAddress
masking_function email()
Step 4: Test as a non-administrative user
If you have a test user, run:
EXECUTE AS USER = ' TestUser ' ;
SELECT TOP (10)
EmailAddress
FROM SalesLT.Customer;
REVERT;
Expected output should look like:
aXXX@XXXX.com
bXXX@XXXX.com
cXXX@XXXX.com
A user with administrative privileges, db_owner, or UNMASK permission can still see the original email value. Microsoft states that users with administrative rights such as server admin, Microsoft Entra admin, and db_owner can view the original unmasked data.
Method 2 — Azure Portal Method
Use this if the simulation expects portal configuration.
Step 1: Open db1
Sign in to the Azure portal.
Search for SQL databases.
Open database:
db1
Step 2: Open Dynamic Data Masking
From the db1 page:
Security > Dynamic Data Masking
Microsoft states that for Azure SQL Database, Dynamic Data Masking can be configured in the Azure portal from the SQL database configuration pane under Security > Dynamic Data Masking.
Step 3: Add a masking rule
Add a mask for the email column:
Setting
Value
Schema
SalesLT
Table
Customer
Column
EmailAddress
Masking field format
Masking function
email()
Then select:
Save
The portal may show the mask type simply as:
That is the correct option because it maps to the email() masking function.
Important Permission Check
Dynamic Data Masking only affects users who do not have permission to view unmasked data.
If a non-administrative user was previously granted UNMASK, remove it:
REVOKE UNMASK TO [UserName];
Or, if a role was granted UNMASK, revoke it from the role:
REVOKE UNMASK TO [RoleName];
Do not grant UNMASK to normal users. UNMASK allows users to bypass masking and see the original values. Microsoft documents that UNMASK permission controls whether users can view masked or original data.
Final Exam-Lab Action
Run this against db1:
ALTER TABLE [SalesLT].[Customer]
ALTER COLUMN [EmailAddress]
ADD MASKED WITH (FUNCTION = ' email() ' );
Then verify:
SELECT
OBJECT_SCHEMA_NAME(object_id) AS schema_name,
OBJECT_NAME(object_id) AS table_name,
name AS column_name,
masking_function
FROM sys.masked_columns
WHERE OBJECT_SCHEMA_NAME(object_id) = ' SalesLT '
AND OBJECT_NAME(object_id) = ' Customer '
AND name = ' EmailAddress ' ;
The task is complete when non-administrative users querying SalesLT.Customer.EmailAddress see masked email values such as:
aXXX@XXXX.com
You need to implement the surrogate key for the retail store table. The solution must meet the sales transaction dataset requirements.
What should you create?
a table that has a FOREIGN KEY constraint
a table the has an IDENTITY property
a user-defined SEQUENCE object
a system-versioned temporal table
The Answer Is:
BExplanation:
Scenario: Contoso requirements for the sales transaction dataset include:
Implement a surrogate key to account for changes to the retail store addresses.
A surrogate key on a table is a column with a unique identifier for each row. The key is not generated from the
table data. Data modelers like to create surrogate keys on their tables when they design data warehouse models. You can use the IDENTITY property to achieve this goal simply and effectively without affecting load performance.
You need to design a data retention solution for the Twitter feed data records. The solution must meet the customer sentiment analytics requirements.
Which Azure Storage functionality should you include in the solution?
time-based retention
change feed
lifecycle management
soft delete
The Answer Is:
CExplanation:
The lifecycle management policy lets you:
Delete blobs, blob versions, and blob snapshots at the end of their lifecycles
