ARA-C01 Snowflake SnowPro Advanced: Architect Certification Exam Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Snowflake ARA-C01 SnowPro Advanced: Architect Certification Exam certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
An Architect has been asked to clone schema STAGING as it looked one week ago, Tuesday June 1st at 8:00 AM, to recover some objects.
The STAGING schema has 50 days of retention.
The Architect runs the following statement:
CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-06-01 08:00:00');
The Architect receives the following error: Time travel data is not available for schema STAGING. The requested time is either beyond the allowed time travel period or before the object creation time.
The Architect then checks the schema history and sees the following:
CREATED_ON|NAME|DROPPED_ON
2021-06-02 23:00:00 | STAGING | NULL
2021-05-01 10:00:00 | STAGING | 2021-06-02 23:00:00
How can cloning the STAGING schema be achieved?
A group of Data Analysts have been granted the role analyst role. They need a Snowflake database where they can create and modify tables, views, and other objects to load with their own data. The Analysts should not have the ability to give other Snowflake users outside of their role access to this data.
How should these requirements be met?
What is a valid object hierarchy when building a Snowflake environment?
A company is designing its serving layer for data that is in cloud storage. Multiple terabytes of the data will be used for reporting. Some data does not have a clear use case but could be useful for experimental analysis. This experimentation data changes frequently and is sometimes wiped out and replaced completely in a few days.
The company wants to centralize access control, provide a single point of connection for the end-users, and maintain data governance.
What solution meets these requirements while MINIMIZING costs, administrative effort, and development overhead?
Which of the below commands will use warehouse credits?
An Architect is designing partitioned external tables for a Snowflake data lake. The data lake size may grow over time, and partition definitions may need to change in the future.
How can these requirements be met?
Following objects can be cloned in snowflake
How can an Architect enable optimal clustering to enhance performance for different access paths on a given table?
The following statements have been executed successfully:
USE ROLE SYSADMIN;
CREATE OR REPLACE DATABASE DEV_TEST_DB;
CREATE OR REPLACE SCHEMA DEV_TEST_DB.SCHTEST WITH MANAGED ACCESS;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
GRANT USAGE ON DATABASE DEV_TEST_DB TO ROLE ANALYST_PROJ;
GRANT USAGE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE ANALYST_PROJ;
GRANT CREATE TABLE ON SCHEMA DEV_TEST_DB.SCHTEST TO ROLE DEV_PROJ_OWN;
USE ROLE DEV_PROJ_OWN;
CREATE OR REPLACE TABLE DEV_TEST_DB.SCHTEST.CURRENCY (
COUNTRY VARCHAR(255),
CURRENCY_NAME VARCHAR(255),
ISO_CURRENCY_CODE VARCHAR(15),
CURRENCY_CD NUMBER(38,0),
MINOR_UNIT VARCHAR(255),
WITHDRAWAL_DATE VARCHAR(255)
);
The role hierarchy is as follows (simplified from the diagram):
ACCOUNTADMIN└─ DEV_SYSADMIN└─ DEV_PROJ_OWN└─ ANALYST_PROJ
Separately:
ACCOUNTADMIN└─ SYSADMIN└─ MAPPING_ROLE
Which statements will return the records from the table
DEV_TEST_DB.SCHTEST.CURRENCY? (Select TWO)

An Architect has a design where files arrive every 10 minutes and are loaded into a primary database table using Snowpipe. A secondary database is refreshed every hour with the latest data from the primary database.
Based on this scenario, what Time Travel query options are available on the secondary database?
An Architect needs to design a data unloading strategy for Snowflake, that will be used with the COPY INTO <location> command.
Which configuration is valid?
What are some of the characteristics of result set caches? (Choose three.)
A Developer is having a performance issue with a Snowflake query. The query receives up to 10 different values for one parameter and then performs an aggregation over the majority of a fact table. It then
joins against a smaller dimension table. This parameter value is selected by the different query users when they execute it during business hours. Both the fact and dimension tables are loaded with new data in an overnight import process.
On a Small or Medium-sized virtual warehouse, the query performs slowly. Performance is acceptable on a size Large or bigger warehouse. However, there is no budget to increase costs. The Developer
needs a recommendation that does not increase compute costs to run this query.
What should the Architect recommend?
A global company needs to securely share its sales and Inventory data with a vendor using a Snowflake account.
The company has its Snowflake account In the AWS eu-west 2 Europe (London) region. The vendor's Snowflake account Is on the Azure platform in the West Europe region. How should the company's Architect configure the data share?
User1 and User2 are new users that were granted different functional roles.
User1 was granted the IT_ANALYST_ROLE
User2 was granted the FIN_ANALYST_ROLE
Review the following security design (as shown in the diagram):
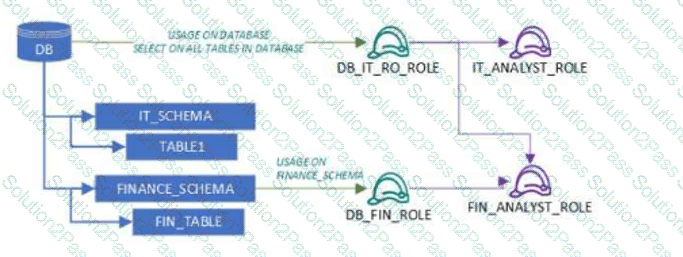
A database (DB) grants USAGE and SELECT on all tables to DB_IT_RO_ROLE
DB_IT_RO_ROLE is granted to IT_ANALYST_ROLE
IT_SCHEMA contains TABLE1
FINANCE_SCHEMA grants USAGE and SELECT to DB_FIN_ROLE
DB_FIN_ROLE is granted to FIN_ANALYST_ROLE
FINANCE_SCHEMA contains FIN_TABLE
Which tables can each user read?
An Architect has designed a data pipeline that Is receiving small CSV files from multiple sources. All of the files are landing in one location. Specific files are filtered for loading into Snowflake tables using the copy command. The loading performance is poor.
What changes can be made to Improve the data loading performance?
An Architect needs to automate the daily Import of two files from an external stage into Snowflake. One file has Parquet-formatted data, the other has CSV-formatted data.
How should the data be joined and aggregated to produce a final result set?
The Business Intelligence team reports that when some team members run queries for their dashboards in parallel with others, the query response time is getting significantly slower What can a Snowflake Architect do to identify what is occurring and troubleshoot this issue?
A)

B)

C)

D)

What Snowflake features should be leveraged when modeling using Data Vault?
A company’s table, employees, was accidentally replaced with a new version.
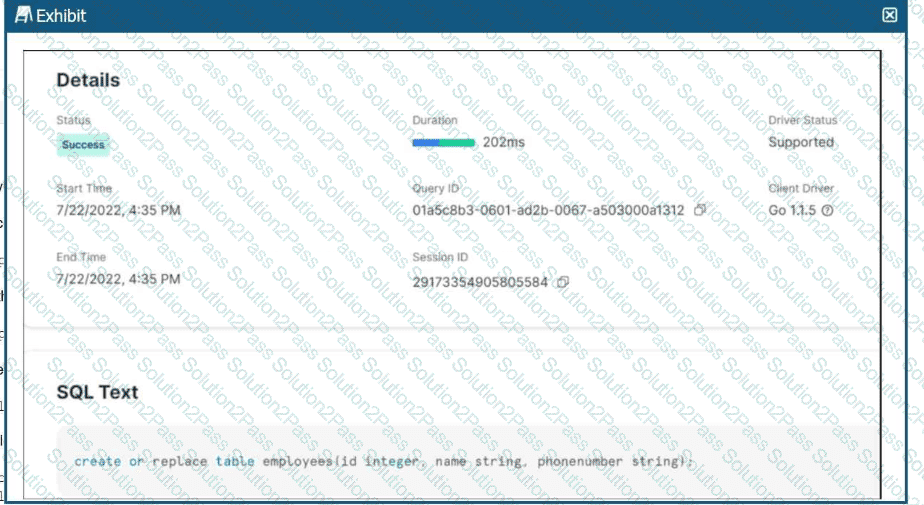
How can the original table be recovered with the LEAST operational overhead?
