Data-Engineer-Associate Amazon Web Services AWS Certified Data Engineer - Associate (DEA-C01) Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Amazon Web Services Data-Engineer-Associate AWS Certified Data Engineer - Associate (DEA-C01) certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
Total 302 questions
A company uses a variety of AWS and third-party data stores. The company wants to consolidate all the data into a central data warehouse to perform analytics. Users need fast response times for analytics queries.
The company uses Amazon QuickSight in direct query mode to visualize the data. Users normally run queries during a few hours each day with unpredictable spikes.
Which solution will meet these requirements with the LEAST operational overhead?
A company analyzes data in a data lake every quarter to perform inventory assessments. A data engineer uses AWS Glue DataBrew to detect any personally identifiable information (PII) about customers within the data. The company ' s privacy policy considers some custom categories of information to be PII. However, the categories are not included in standard DataBrew data quality rules.
The data engineer needs to modify the current process to scan for the custom PII categories across multiple datasets within the data lake.
Which solution will meet these requirements with the LEAST operational overhead?
A retail company is using an Amazon Redshift cluster to support real-time inventory management. The company has deployed an ML model on a real-time endpoint in Amazon SageMaker.
The company wants to make real-time inventory recommendations. The company also wants to make predictions about future inventory needs.
Which solutions will meet these requirements? (Select TWO.)
A company that operates globally must follow regulations that require data from an AWS Region to be accessible only within that Region.
A data engineer is creating a data pipeline that will create resources in the Region where the data engineer works. The data pipeline should have access to data only from the Region where the data engineer works. The pipeline uses Active Directory as an identity and authentication system. The pipeline uses a custom identity broker application to verify that employees are signed in to Active Directory and to obtain temporary credentials by using the AssumeRole API operation.
Which solution will meet the locality requirements with the LEAST administrative effort?
A data engineer is designing a new data lake architecture for a company. The data engineer plans to use Apache Iceberg tables and AWS Glue Data Catalog to achieve fast query performance and enhanced metadata handling. The data engineer needs to query historical data for trend analysis and optimize storage costs for a large volume of event data.
Which solution will meet these requirements with the LEAST development effort?
A data engineer is optimizing query performance in Amazon Athena notebooks that use Apache Spark to analyze large datasets that are stored in Amazon S3. The data is partitioned. An AWS Glue crawler updates the partitions.
The data engineer wants to minimize the amount of data that is scanned to improve efficiency of Athena queries.
Which solution will meet these requirements?
A data engineer needs to run a data transformation job whenever a user adds a file to an Amazon S3 bucket. The job will run for less than 1 minute. The job must send the output through an email message to the data engineer. The data engineer expects users to add one file every hour of the day.
Which solution will meet these requirements in the MOST operationally efficient way?
A manufacturing company wants to collect data from sensors. A data engineer needs to implement a solution that ingests sensor data in near real time.
The solution must store the data to a persistent data store. The solution must store the data in nested JSON format. The company must have the ability to query from the data store with a latency of less than 10 milliseconds.
Which solution will meet these requirements with the LEAST operational overhead?
A company implements a data mesh that has a central governance account. The company needs to catalog all data in the governance account. The governance account uses AWS Lake Formation to centrally share data and grant access permissions.
The company has created a new data product that includes a group of Amazon Redshift Serverless tables. A data engineer needs to share the data product with a marketing team. The marketing team must have access to only a subset of columns. The data engineer needs to share the same data product with a compliance team. The compliance team must have access to a different subset of columns than the marketing team needs access to.
Which combination of steps should the data engineer take to meet these requirements? (Select TWO.)
A company stores daily records of the financial performance of investment portfolios in .csv format in an Amazon S3 bucket. A data engineer uses AWS Glue crawlers to crawl the S3 data.
The data engineer must make the S3 data accessible daily in the AWS Glue Data Catalog.
Which solution will meet these requirements?
A data engineer must orchestrate a series of Amazon Athena queries that will run every day. Each query can run for more than 15 minutes.
Which combination of steps will meet these requirements MOST cost-effectively? (Choose two.)
A banking company uses an application to collect large volumes of transactional data. The company uses Amazon Kinesis Data Streams for real-time analytics. The company ' s application uses the PutRecord action to send data to Kinesis Data Streams.
A data engineer has observed network outages during certain times of day. The data engineer wants to configure exactly-once delivery for the entire processing pipeline.
Which solution will meet this requirement?
A university is developing an educational application that analyzes student essays. The application provides personalized feedback with accurate citations to the university ' s textbooks. The application needs to process essays in multiple languages. Application responses must include direct references to specific sections in the course materials and must be in the student ' s selected language.
Which solution will meet these requirements with the LEAST operational overhead?
A healthcare company uses Amazon Kinesis Data Streams to stream real-time health data from wearable devices, hospital equipment, and patient records.
A data engineer needs to find a solution to process the streaming data. The data engineer needs to store the data in an Amazon Redshift Serverless warehouse. The solution must support near real-time analytics of the streaming data and the previous day ' s data.
Which solution will meet these requirements with the LEAST operational overhead?
A company has a production AWS account that runs company workloads. The company ' s security team created a security AWS account to store and analyze security logs from the production AWS account. The security logs in the production AWS account are stored in Amazon CloudWatch Logs.
The company needs to use Amazon Kinesis Data Streams to deliver the security logs to the security AWS account.
Which solution will meet these requirements?
A data engineer needs to create a new empty table in Amazon Athena that has the same schema as an existing table named old-table.
Which SQL statement should the data engineer use to meet this requirement?
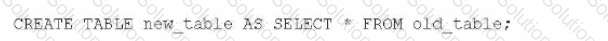
B.
A retail company uses an Amazon Redshift data warehouse and an Amazon S3 bucket. The company ingests retail order data into the S3 bucket every day.
The company stores all order data at a single path within the S3 bucket. The data has more than 100 columns. The company ingests the order data from a third-party application that generates more than 30 files in CSV format every day. Each CSV file is between 50 and 70 MB in size.
The company uses Amazon Redshift Spectrum to run queries that select sets of columns. Users aggregate metrics based on daily orders. Recently, users have reported that the performance of the queries has degraded. A data engineer must resolve the performance issues for the queries.
Which combination of steps will meet this requirement with LEAST developmental effort? (Select TWO.)
A company has a data pipeline that uses an Amazon RDS instance, AWS Glue jobs, and an Amazon S3 bucket. The RDS instance and AWS Glue jobs run in a private subnet of a VPC and in the same security group.
A use ' made a change to the security group that prevents the AWS Glue jobs from connecting to the RDS instance. After the change, the security group contains a single rule that allows inbound SSH traffic from a specific IP address.
The company must resolve the connectivity issue.
Which solution will meet this requirement?
A retail company stores data from a product lifecycle management (PLM) application in an on-premises MySQL database. The PLM application frequently updates the database when transactions occur.
The company wants to gather insights from the PLM application in near real time. The company wants to integrate the insights with other business datasets and to analyze the combined dataset by using an Amazon Redshift data warehouse.
The company has already established an AWS Direct Connect connection between the on-premises infrastructure and AWS.
Which solution will meet these requirements with the LEAST development effort?
A data engineer maintains a materialized view that is based on an Amazon Redshift database. The view has a column named load_date that stores the date when each row was loaded.
The data engineer needs to reclaim database storage space by deleting all the rows from the materialized view.
Which command will reclaim the MOST database storage space?

Total 302 questions
