MLA-C01 Amazon Web Services AWS Certified Machine Learning Engineer - Associate Free Practice Exam Questions (2026 Updated)
Prepare effectively for your Amazon Web Services MLA-C01 AWS Certified Machine Learning Engineer - Associate certification with our extensive collection of free, high-quality practice questions. Each question is designed to mirror the actual exam format and objectives, complete with comprehensive answers and detailed explanations. Our materials are regularly updated for 2026, ensuring you have the most current resources to build confidence and succeed on your first attempt.
An ML engineer is using Amazon SageMaker to train a deep learning model that requires distributed training. After some training attempts, the ML engineer observes that the instances are not performing as expected. The ML engineer identifies communication overhead between the training instances.
What should the ML engineer do to MINIMIZE the communication overhead between the instances?
A company needs to analyze a large dataset that is stored in Amazon S3 in Apache Parquet format. The company wants to use one-hot encoding for some of the columns.
The company needs a no-code solution to transform the data. The solution must store the transformed data back to the same S3 bucket for model training.
Which solution will meet these requirements?
A company needs an AWS solution that will automatically create versions of ML models as the models are created. Which solution will meet this requirement?
An ML engineer is setting up a continuous integration and continuous delivery (CI/CD) pipeline for an ML workflow in Amazon SageMaker AI. The pipeline needs to automate model re-training, testing, and deployment whenever new data is uploaded to an Amazon S3 bucket. New data files are approximately 10 GB in size. The ML engineer wants to track model versions for auditing.
Which solution will meet these requirements?
An ML engineer is building a logistic regression model to predict customer churn for subscription services. The dataset contains two string variables: location and job_seniority_level.
The location variable has 3 distinct values, and the job_seniority_level variable has over 10 distinct values.
The ML engineer must perform preprocessing on the variables.
Which solution will meet this requirement?
A company has a large, unstructured dataset. The dataset includes many duplicate records across several key attributes.
Which solution on AWS will detect duplicates in the dataset with the LEAST code development?
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
A company needs to host a custom ML model to perform forecast analysis. The forecast analysis will occur with predictable and sustained load during the same 2-hour period every day.
Multiple invocations during the analysis period will require quick responses. The company needs AWS to manage the underlying infrastructure and any auto scaling activities.
Which solution will meet these requirements?
An ML engineer trained an ML model on Amazon SageMaker to detect automobile accidents from dosed-circuit TV footage. The ML engineer used SageMaker Data Wrangler to create a training dataset of images of accidents and non-accidents.
The model performed well during training and validation. However, the model is underperforming in production because of variations in the quality of the images from various cameras.
Which solution will improve the model ' s accuracy in the LEAST amount of time?
An ML engineer is designing an AI-powered traffic management system. The system must use near real-time inference to predict congestion and prevent collisions.
The system must also use batch processing to perform historical analysis of predictions over several hours to improve the model. The inference endpoints must scale automatically to meet demand.
Which combination of solutions will meet these requirements? (Select TWO.)
An ML model is deployed in production. The model has performed well and has met its metric thresholds for months.
An ML engineer who is monitoring the model observes a sudden degradation. The performance metrics of the model are now below the thresholds.
What could be the cause of the performance degradation?
An ML engineer has trained an ML model by using Amazon SageMaker AI. The ML engineer determines that the model is overfitting and that the training data contains unnecessary features. The ML engineer must reduce the overfitting and the impact of the unnecessary features.
Which solution will meet these requirements?
A company is using ML to predict the presence of a specific weed in a farmer ' s field. The company is using the Amazon SageMaker linear learner built-in algorithm with a value of multiclass_dassifier for the predictorjype hyperparameter.
What should the company do to MINIMIZE false positives?
A company has an application that uses different APIs to generate embeddings for input text. The company needs to implement a solution to automatically rotate the API tokens every 3 months.
Which solution will meet this requirement?
An ML engineer needs to use AWS CloudFormation to create an ML model that an Amazon SageMaker endpoint will host.
Which resource should the ML engineer declare in the CloudFormation template to meet this requirement?
An ML engineer is collecting data to train a classification ML model by using Amazon SageMaker AI. The target column can have two possible values: Class A or Class B. The ML engineer wants to ensure that the number of samples for both Class A and Class B are balanced, without losing any existing training data. The ML engineer must test the balance of the training data.
Which solution will meet this requirement?
A company has significantly increased the amount of data that is stored as .csv files in an Amazon S3 bucket. Data transformation scripts and queries are now taking much longer than they used to take.
An ML engineer must implement a solution to optimize the data for query performance.
Which solution will meet this requirement with the LEAST operational overhead?
A company wants to deploy an Amazon SageMaker AI model that can queue requests. The model needs to handle payloads of up to 1 GB that take up to 1 hour to process. The model must return an inference for each request. The model also must scale down when no requests are available to process.
Which inference option will meet these requirements?
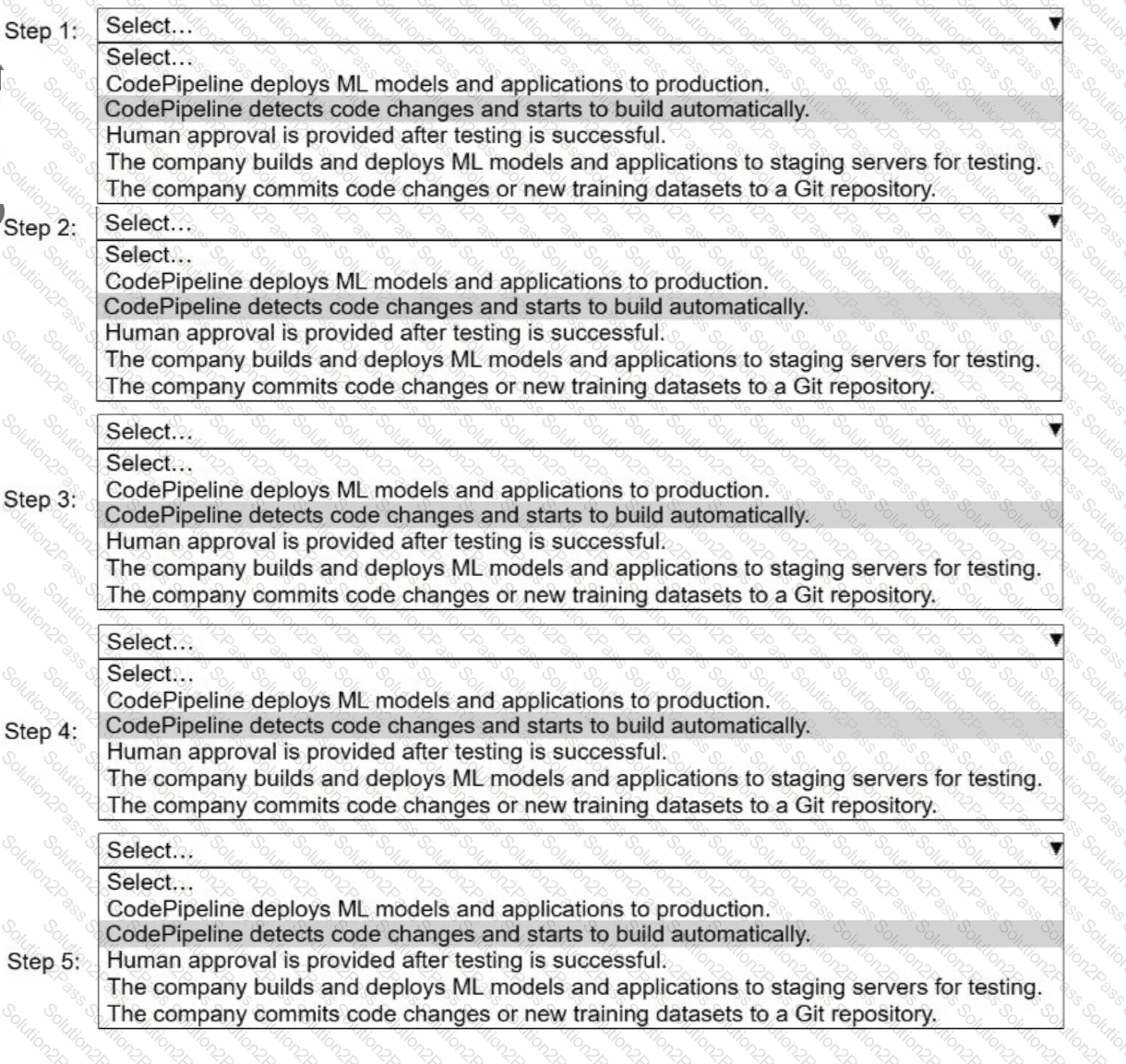
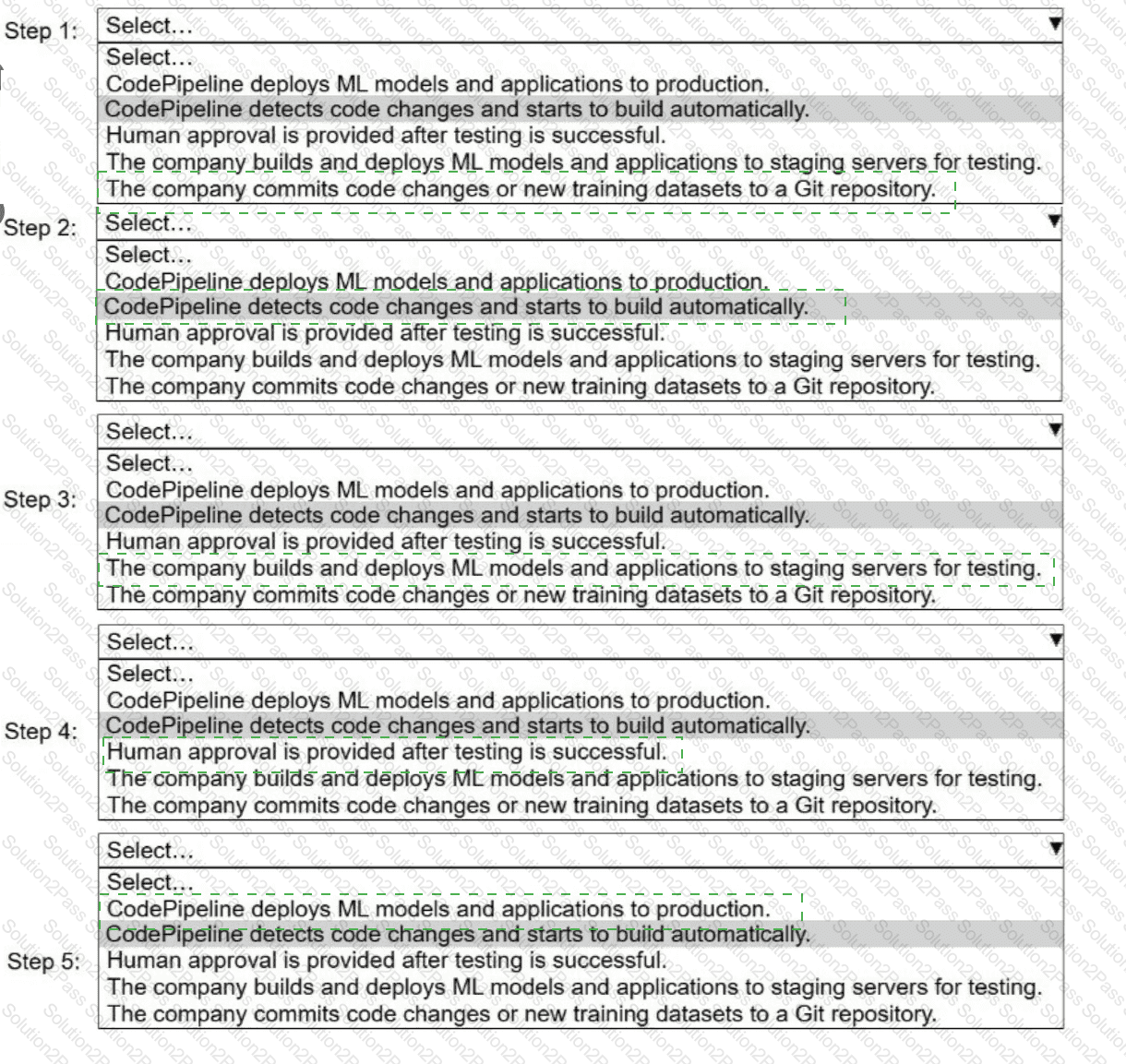
A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
An ML engineer needs to create data ingestion pipelines and ML model deployment pipelines on AWS. All the raw data is stored in Amazon S3 buckets.
Which solution will meet these requirements?
